我们有这样一个系统,每日对数据进行跑批加载,将所有的表分散在多个节点并行跑批,但是一个节点的多张表是并行的,并且cpu一次吊起的节点数只有4个,有这样一张表a_etllog专门纪录这些表的处理情况,由于每日数据加载时间过长,我需要找到一个跑批速度慢的原因,
1.我随意找一天的数据加载情况,就如20131225
select tabname,max(end),min(bengin) froma_etllog where datadate='20131225' group byTABNAME
得到结果如下,
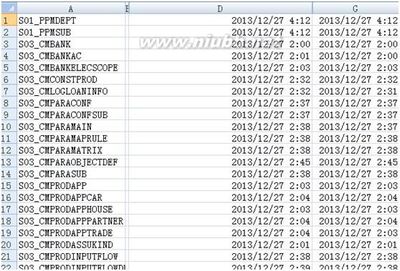
每一行表示的是每张表20131225日加载的结束时间和开始实际,这里的时间规范,可以利用数据库时间的to_char函数的时间格式转变,也可以利用excel自带的设置单元格格式转变,朋友们自己可以尝试一下,
2.需在此excel上作一个每张表的跑批时间统计,算出以秒为单位的时间段,
3.此时可以引出一个华丽丽的函数,FREQUENCY概率,此函数用于计算数值在某个区域内的出现频率,然后返回一个垂直数组
a)首先找出最长时间段和最短时间段的时间段大小,如我现在找出的最短时间为2秒,最长时间为4913秒,因为我们需要将这个范围包括,所以我给定以0开始,5000结束,中间按照10秒递增,形成一个垂直数组,
b)现在我们就是需要利用FREQUENCY函数对这创建的两列进行求分布情况,首先选中与J列一样多的单元格,然后键入=FREQUENCY(h1:h1954,j1:j501)后,按shift+ctrl+enter,即可得到值,该函数表示的意思是从区域h1:h1945里找到属于j1:j501的值的个数)
c)现在我们可以通过上图知道了,表加载时间基本少于60秒的较为密集,查了下面所有的,基本数据也分散,所以可以将区间值做如下修改,即将下面的数值间隔增大,以方便我们查看,
d)通过上图发现,在1000秒到5000秒的区域内有11张表,这是不是一个好现象我们现在无法判断,
4.通过上面的情况,我们把H列按大小排序后,得到这11张表的表名,发现了一个令人兴奋的结果,其中有4张表是在同一个节点,并且这个节点也仅仅只有这四张表(位于同一个节点意味着串行),也就是说,这4张大表,我们做了悲催的串行。
5.如何解决该问题?
a.将此4张表拆分为4个节点,但是我们的系统有个大bug的是一次性只可以调用4个节点,因此此方法舍弃
b.将此4张表并行开来,也就是每张表都直接跑批,不用等上一张表结束才开始,此处用到了伟大的nohup,每张表都需要用nohup来调起,在该节点所有表结束时给一个wait,则实现了并行跑批的功能,万事大吉。
你学会了吗?