TCP重组数据包分析
参照TCP/IP详解第二卷24~29章,详细论述了TCP协议的实现,大概总结一下TCP如何向应用层保证数据包的正确性、可靠性,即TCP如何实现对数据报文的重组。
首先要设计两个报文队列,一个存放正常来到的报文,一个存放失序到来的报文。
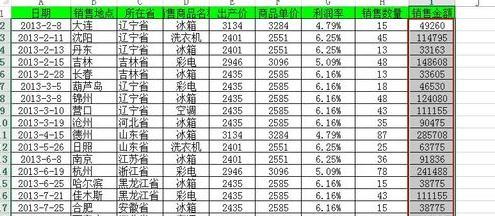
比如正常报文队列最后一个报文数据如下:
报文数据段第一字节的序号数据报长度
seq1=100 | len1=100  |
下一个来到的报文可能有多种情况,现依次分析如下:
1)正常报文
seq2=200 | len2=200 |
seq2 = seq1+len1
由此报文的seq可知,这个报文携带数据序号200~399,正是上一个报文的预期后续报文,将此报文追加到正常报文队列。
2)完全重复报文
seq2=100 | len2=100 |
seq2 ==seq1 而且len2==len1
这个报文携带数据序号100~199,与上一个报文携带的数据序号100~199完全一样,即完全重复,所以应该丢弃这个报文。
3)重复子报文
seq2=100 | len2=50 |
seq2 ==seq1 而且len2<len1
这个报文携带数据序号100~149,说明这是上一个报文的一部分,所以应该丢弃这个报文。
注:第二、三这两种情况可以合并,即seq2 ==seq1而且len2<=len1,这里分别列出只是为了说明各种不同情况。
4)部分重复报文情况一
seq2=150 | len2=30 |
seq2>seq1而且seq2<seq1+len1而且seq2+len2<=seq1+len1
即这个报文携带序号150~179,这个序号段被包含在上一个报文段中(100~199),
所以应该丢弃这个报文。
5)部分重复报文情况二
seq2=150 | len2=100 |
seq2>seq1而且seq2<seq1+len1而且seq2+len2>seq1+len1
即这个报文携带序号150~249,这个序号段前一部分150~199被包含在上一个报文段(100~199)中,后一部分200~249是新的数据,此时应该对这个报文作如下处理:
A.计算重复字节数
(seq1+len1) - Seq2= 100+100-150 = 50
即这个报文段前50个字节是重复的。
B.截取报文段新数据
丢弃这个报文段的前50字节,截取后面的新数据,即只保留字节序号段200~249。
C.重新设置这个报文段的seq
seq2 = seq2+50 = 150+50 = 200
D.重新设置这个报文段的数据长度
len2 = len2-50 =100-50=50
E.重新设置后报文段如下
seq2=200 | len2=50 |
即现在这个报文段携带数据序号200~249,正好是上一个报文的后续报文,现在可以将其作为正常报文追加到正常报文队列。
6)提前到达的报文
seq2=300 | len2=100 |
seq2>seq1+len1
这个报文段携带序号300~399的数据,即不是上一个报文100~199的后续报文,而是提前到来的报文,此时应该将这个报文放置到失序报文队列存储起来,以备后续重组使用。
这样直到tcp断开这个socket的链接(FIN=1),此时将正常报文队列和失序报文队列中的数据合并起来,完成重组。取出正常报文队列最后一个报文的seq和len,在失序报文队列中查找属于它的后续报文,该报文是否可以作为正常报文队列的后续报文处理过程同前面1)~5)的分析。