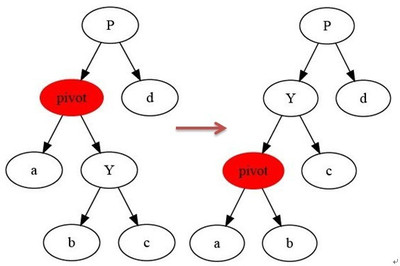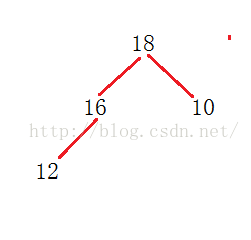
不谈内存,从算法上来讲红黑树插入是最坏情况要比较2logN次(最高的高度)外加不超过两次旋转,最小堆最坏情况是logN次红黑树删除不需要比较只需要不超过3旋转,查找最小值需要遍历logN,如果删除最小值树调整一般很小最小堆查询顶节点是O(1),而删除顶节点在任何情况下都是个最坏的情况,需要比较2logN次红黑树的最坏情况在旋转中不断调整变化,插入性能比最小堆差,但删除最小性能却比最小堆好上几倍如果插入+查找最小+删除最小总体来确定红黑树和最小堆,红黑树占优,性能波动相对较小,红黑树不过多的依赖比较,相对最小堆由比较带来的的性能影响较小(如果比较是调用自定义函数、比较的是字符串等,那么性能就牺牲很大)最小堆最大的优势在于取最小值性能是O(1),如果插入的数据基本有序,那么最小堆能获得比较好的性能,在频繁不断地取最小值的是否满足条件的应用中有更加好的性能(如超时队列),红黑树相应就要尽量避免不必要的查询次数才能在超时队列这种应用中获得更好的性能从实际出发:由于最小堆一般是采用堆的方式实现,元素访问速度远高于采用链表方式的红黑树,插入性能快红黑树好几倍,但最小堆的删除性能并不快于红黑树最小堆的最大缺点就在于必须是连续的内存测试环境:vmware虚拟机内存1G,cpu1,centos 64, 物理cpu i5 3210m 编译 O2优化,内存预先分配,数据预先生成千万级(0-10000000)链表方式实现的最小堆,每次插入删除都会涉及到后继和前驱的问题,算法复杂度高一点(从测试结果来看还比较理想)逆序,删除最小红黑树:insert use time 4.856delete use time 2.142最小堆:insert use time 1.021delete use time 2.015链表实现最小堆:insert use time 3.043delete use time 3.179
顺序:红黑树:insert use time 5.672delete use time 1.910最小堆:insert use time 0.178delete use time 3.049
链表实现最小堆:insert use time0.243delete use time 4.834
随机(测试序列都是一样,srand(100),然后千万次rand()):红黑树:insert use time 15.264delete use time 1.136最小堆:insert use time 0.361delete use time 21.272链表实现最小堆:insert use time0.524delete use time 21.984