故事来由
本人以前有一小站www.daaata.com刊登几篇关于利用SAS抓取网页数据的小文,然后挂了个链接在人大论坛。后因懒惰,此站挂掉,相继有人询问。在从新有此博后打
算把其中一篇简单易懂的补上,另外几篇译文已被@统计网收录,文章末尾会贴上链接。
适用性
下面的此案例相同方式理论都可以进去获取。
P.S. @AJAX数据库实例|| @AJAX数据库实例讲解
正文
前戏
有时我们常常需要保存备份某些网上的数据,如银行利率,股票行情,抑或统计局、各种金融机构或其他类型网站的数据。有时这些网站会提供历史数据,有的则不会。但是我们可以通过SAS每天跑下程序获取累积历史数据作为后来的分析之用。现在我拿获取http://www.shibor.org/主页,上海银行间同业拆放利率,作为案例进行演示。
以下为主页上我们想要的数据
当我们打开此网页,并进到网页源码中时,我们会惊讶的发现。什么情况,在主页上看到的数据在源码里找不到,难道使用了别的技术。我们大概浏览一下源码所表示的
网页布局。
按网页布局来说,一大坨文字的后面就应该放最新Shibor数据的源码,而他放了一句。
<iframe scrolling="no" src ="/shibor/web/html/shibor.html" width="377" height="473" frameborder="0" name="shibordata"></iframe>这是html内联框架结构,就是说他把数据放另一个网页上了,然后把这个网页嵌在主页里。好,那我们就打开此网页
http://www.shibor.org/shibor/web/html/shibor.html并查看源码,发现数据就存在此网页中,那我们就开始用SAS抓它一下。
高潮
首先介绍下Filename,利用它加上infile语句就可以把网页当成文件导入SAS数据集。 TheFILENAME Statement (URL Access Method) in BaseSAS, enables users to access the source code from a web site andread it into a data set. The syntax for this statement is:
FILENAME fileref URL 'external-file'<url-options>;把Shibor数据网页导入SAS数据集。我们知道网页数据是标记语言,服从一定规范,所有属性设置都被<>包含。所以我们利用dlm=">"把它分隔导入到一个变量中,因为数据太乱,我们没法分清使之导入到不同变量。
FILENAME SOURCE URL "%STR(http://www.shibor.org/shibor/web/html/shibor.html)" DEBUG;DATA Zhaocl01; FORMAT WEBPAGE $1000.; INFILE SOURCE LRECL=32767 DELIMITER=">"; INPUT WEBPAGE $ @@;RUN;
因为我们利用了dlm=">"进行了分隔,所以我们清楚收集到的观测值只要以<开头就说明这条观测只有设置语言,没有我们想要的数据。而我们真正要要的数据肯定都在<标识符的前面。因为在网页源码中会用 代表空格,&代表连字符,所以把他们进行替换。
DATA Zhaocl02; SET Zhaocl01; WHERE WEBPAGE LIKE "_%<%"; TEXT=SUBSTRN(WEBPAGE,1,FIND(WEBPAGE,"<")-1); TEXT=TRANWRD(TEXT,"%NRSTR()"," "); TEXT=TRANWRD(TEXT,"%NRSTR(&)","&"); IF ANYALPHA(TEXT) + ANYDIGIT(TEXT) LT 1 THEN DELETE; KEEP TEXT;RUN;
结局
拿到了清理后的数据集,打开看下已经很清楚了。我们只要再做下最后简单的加工就好了。注意,由于网页布局的变动这段程序也可能要随之稍加修改。
data Zhaocl03; set Zhaocl02; set Zhaocl02(firstobs=2 rename=(text=next1)); set Zhaocl02(firstobs=3 rename=(text=next2)); if text in ("O/N","1W","2W","1M","3M","6M","9M","1Y"); label text='期限' next1='Shibor(%)' next2='涨跌(BP)'; run; proc print label;run;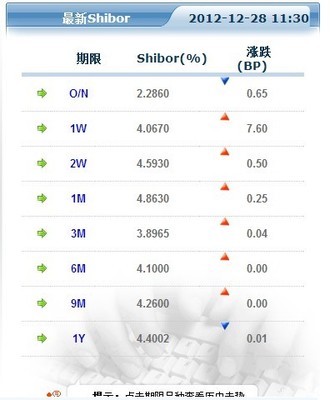
其他
正则表达式
在处理网页数据时,有一个利器就是正则表达式,威力巨大。比如:
prxchange("s/<.+?>//",-1,WEBPAGE ); 就可以去除所有<>包含的内容。但是一定要在对自己获取数据了解十分透彻的情况下使用,以防遗漏重要信息。
相关资源
A Guide to Crawling the Web with SAS? http://www.sascommunity.org/wiki/Simple_Web_Crawler_with_SAS_Macro_and_SAS_Data_Stephttp://support.sas.com/resources/papers/proceedings10/053-2010.pdf
被收录的译文,网络爬虫—利用SAS抓取网页方法 http://www.itongji.cn/article/0221O62012.htmlhttp://www.itongji.cn/article/0221OR012.html
转载自:http://zhaocl.com/code/2012/12/30/web-crawler-1.html
备注:配合fiddler一起使用,基本上所有的页面内容(静态的,动态的,异步加载的等)都可以抓的到了!