六框阅读翻译DNA序列 dna序列分析软件
usestrict;
usewarnings;
my$dna='';
my$protein='';
my@file_data=();
my@filedata;
my$revcom='';
#打开文件
@filedata=get_file_data();
#得到序列
$dna=extract_sequence_from_fasta_data(@filedata);
#六框阅读翻译
print"n---------------------ReadingFrame1-----------------n";
$protein=translate_frame($dna,1);
print_sequence($protein,70);
print"n---------------------ReadingFrame2-----------------n";
$protein=translate_frame($dna,2);
print_sequence($protein,70);
print"n---------------------ReadingFrame3-----------------n";
$protein=translate_frame($dna,3);
print_sequence($protein,70);
print"n---------------------ReadingFrame4-----------------n";
$protein=translate_frame($dna,4);
print_sequence($protein,70);
print"n---------------------ReadingFrame5-----------------n";
$protein=translate_frame($dna,5);
print_sequence($protein,70);
print"n---------------------ReadingFrame6-----------------n";
$protein=translate_frame($dna,6);
print_sequence($protein,70);
subget_file_data
{
#Asubroutinetogetdatafromafilegivenitsfilename
#读取文件的子序列
my$dna_filename;
my@filedata;
print"pleaseinputthePathjustlikethisf:\\perl\\data.txtn";
chomp($dna_filename=<STDIN>);
open(DNAFILENAME,$dna_filename)||die("cannotopenthefile!");
@filedata=<DNAFILENAME>;
closeDNAFILENAME;
return@filedata;#子函数的返回值一定要记住写
}
subextract_sequence_from_fasta_data
{
#*******************************************************************
#AsubroutinetoextractFASTAsequencedatafromanarray
#得到其中的序列
#fasta格式介绍:
#包括三个部分
#1.第一行中以>开头的注释行,后面是名称和序列的来源
#2.标准单字母符号的序列
#3.*表示结尾
#*******************************************************************
my(@fasta_file_data)=@_;
my$sequence='';
foreachmy$line(@fasta_file_data)
{
#这里忽略空白行
if($line=~/^s*$/)
{
next;
}
#忽略注释行
elsif($line=~/^s*#/)
{
next;
}
#忽略fasta的第一行
elsif($line=~/^>/)
{
next;
}
else
{
$sequence.=$line;
}
}
$sequence=~s/s//g;
return$sequence;
}
subprint_sequence
{
#Asubroutinetoformatandprintsequencedata
my($sequence,$length)=@_;
for(my$pos=0;$pos<length($sequence);$pos+=$length)
{
printsubstr($sequence,$pos,$length),"n";
}
}
subcodon2aa
{
#第三种方法
#也就是运用哈希
#我们将所有的密码子作为hash的key,然后将代表的氨基酸作为hash的value
#然后进行匹配
#codon2aa
#AsubroutinetotranslateaDNA3-charactercodontoanaminoacid
#Version3,usinghashlookup
my($codon)=@_;
$codon=uc$codon;#uc=uppercase;lc=lowercase
#也就是大小写转换,uc表示将所有的小写转换为大写
#lc将所有的大写转换为小写
my(%genetic_code)=(
'TCA'=>'S',#Serine
'TCC'=>'S',#Serine
'TCG'=>'S',#Serine
'TCT'=>'S',#Serine
'TTC'=>'F',#Phenylalanine
'TTT'=>'F',#Phenylalanine
'TTA'=>'L',#Leucine
'TTG'=>'L',#Leucine
'TAC'=>'Y',#Tyrosine
'TAT'=>'Y',#Tyrosine
'TAA'=>'_',#Stop
'TAG'=>'_',#Stop
'TGC'=>'C',#Cysteine
'TGT'=>'C',#Cysteine
'TGA'=>'_',#Stop
'TGG'=>'W',#Tryptophan
'CTA'=>'L',#Leucine
'CTC'=>'L',#Leucine
'CTG'=>'L',#Leucine
'CTT'=>'L',#Leucine
'CCA'=>'P',#Proline
'CCC'=>'P',#Proline
'CCG'=>'P',#Proline
'CCT'=>'P',#Proline
'CAC'=>'H',#Histidine
'CAT'=>'H',#Histidine
'CAA'=>'Q',#Glutamine
'CAG'=>'Q',#Glutamine
'CGA'=>'R',#Arginine
'CGC'=>'R',#Arginine
'CGG'=>'R',#Arginine
'CGT'=>'R',#Arginine
'ATA'=>'I',#Isoleucine
'ATC'=>'I',#Isoleucine
'ATT'=>'I',#Isoleucine
'ATG'=>'M',#Methionine
'ACA'=>'T',#Threonine
'ACC'=>'T',#Threonine
'ACG'=>'T',#Threonine
'ACT'=>'T',#Threonine
'AAC'=>'N',#Asparagine
'AAT'=>'N',#Asparagine
'AAA'=>'K',#Lysine
'AAG'=>'K',#Lysine
'AGC'=>'S',#Serine
'AGT'=>'S',#Serine
'AGA'=>'R',#Arginine
'AGG'=>'R',#Arginine
'GTA'=>'V',#Valine
'GTC'=>'V',#Valine
'GTG'=>'V',#Valine
'GTT'=>'V',#Valine
'GCA'=>'A',#Alanine
'GCC'=>'A',#Alanine
'GCG'=>'A',#Alanine
'GCT'=>'A',#Alanine
'GAC'=>'D',#AsparticAcid
'GAT'=>'D',#AsparticAcid
'GAA'=>'E',#GlutamicAcid
'GAG'=>'E',#GlutamicAcid
'GGA'=>'G',#Glycine
'GGC'=>'G',#Glycine
'GGG'=>'G',#Glycine
'GGT'=>'G',#Glycine
);
if(exists$genetic_code{$codon})
{
return$genetic_code{$codon};
}
else
{
printSTDERR"Badcodon"$codon"!!n";
exit;
}
}
subdna2peptide
{
my($dna)=@_;
my$protein='';
for(my$i=0;$i<(length($dna)-2);$i+=3)
{
$protein.=codon2aa(substr($dna,$i,3));
}
return$protein;#这个词错误找了一晚上,没有返回值,所以结果总是没有内容,以后要引以为戒,子程序一定要有返回值
}
subtranslate_frame
{
my($seq,$start,$end)=@_;
my$protein;
unless($end)
{
$end=length($seq);
}
returndna2peptide(substr($seq,$start-1,$end-$start+1));
}
更多阅读

PDF如何在线阅读 pdf在线阅读
PDF如何在线阅读——简介有时候电脑没有安装pdf软件那么就没法打开了,在线阅读的有好多英文的比较麻烦,接下来给大家讲一个简单的方法就是用网盘阅读,如百度网盘、360网盘,还有126邮箱都可以,接下来我们进入百度网盘PDF如何在线阅读——

小学4年级数奥题含答案 六年级阅读训练含答案
一、填空。(共20分,每小题2分) 1.被除数是3320,商是150,余数是20,除数是()。 2.3998是4个连续自然数的和,其中最小的数是( )。 3.有一个两位数,在它的某一位数字的前面加上一个小数点,再和这个两位数相加,得数是20.9。这个两位数是( ) 4.填
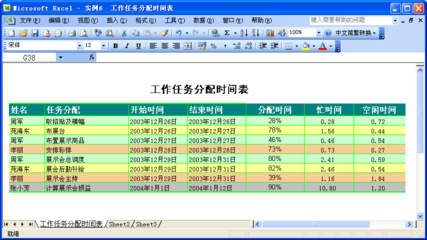
Word2003在打开文档时可能会出现“对话框打开时命令无法执行。单 cad命令对话框
Word2003在打开文档时可能会出现“对话框打开时命令无法执行。单击“确定”,关闭对话框以继续。”是某些杀毒软件(比如瑞星2006)对OFFICE2003支持不好造成的,在杀毒软件的设置中,启用了office插件的保护功能,去掉选项,打开Word文件时就
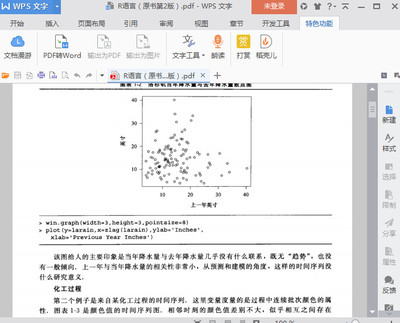
阿村屌丝生活记之--时间序列分析 时间序列分析及应用
时间序列分析一、时间序列数据1.数据类型:截面数据与时间序列数据人们对统计数据往往可以根据其特点从两个方面来切入,以简化分析过程。一个是研究所谓横截面(crosssection)数据,也就是对大体上同时,或者和时间无关的不同对象的观测值组

雅思真题第一册阅读翻译Aspark,aflint:Howfireleapttolife
1. A spark, a flint: How fire leaptto life火花,打火石:火如何改变生活2. The control of fire was the first and perhaps greatest ofhumanity's steps towards a life-enhancing technology.控制火是人类最早,或许是最伟大的提