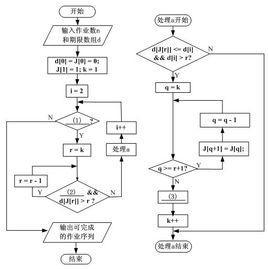
KMeans算法的基本思想是初始随机给定K个簇中心,按照最邻近原则把待分类样本点分到各个簇。然后按平均法重新计算各个簇的质心,从而确定新的簇心。一直迭代,直到簇心的移动距离小于某个给定的值。
K-Means聚类算法主要分为三个步骤:
(1)第一步是为待聚类的点寻找聚类中心
(2)第二步是计算每个点到聚类中心的距离,将每个点聚类到离该点最近的聚类中去
(3)第三步是计算每个聚类中所有点的坐标平均值,并将这个平均值作为新的聚类中心
反复执行(2)、(3),直到聚类中心不再进行大范围移动或者聚类次数达到要求为止
下图展示了对n个样本点进行K-means聚类的效果,这里k取2:
(a)未聚类的初始点集
(b)随机选取两个点作为聚类中心
(c)计算每个点到聚类中心的距离,并聚类到离该点最近的聚类中去
(d)计算每个聚类中所有点的坐标平均值,并将这个平均值作为新的聚类中心
(e)重复(c),计算每个点到聚类中心的距离,并聚类到离该点最近的聚类中去
(f)重复(d),计算每个聚类中所有点的坐标平均值,并将这个平均值作为新的聚类中心
Matlab实现:
详见:http://www.oschina.net/code/snippet_176897_10239
执行结果:
>> Kmeans
6 iterations, total sum of distances = 204.821
10 iterations, total sum of distances = 205.886
16 iterations, total sum of distances = 204.821
9 iterations, total sum of distances = 205.886
........
9 iterations, total sum of distances = 205.886
8 iterations, total sum of distances = 204.821
8 iterations, total sum of distances = 204.821
14 iterations, total sum of distances = 205.886
14 iterations, total sum of distances = 205.886
6 iterations, total sum of distances = 204.821
Ctrs =
1.0754 -1.0632
1.04821.3902
-1.1442 -1.1121
SumD =
64.2944
63.5939
76.9329
聚类效果:
Matlab R2012a Documentation:
http://www.mathworks.com.sixxs.org/help/toolbox/stats/kmeans.html?nocookie=true
stackoverflow:kmeans example in matlab does not run:
http://stackoverflow.com/questions/8411117/kmeans-example-in-matlab-does-not-run