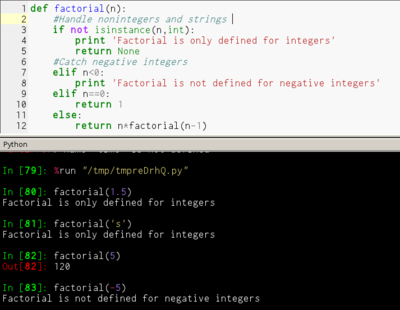
简而言之,就是比如文法是
S→T,T→FM,F→+M,M→a
用伪代码表示这个文法
则首先要写procedureS
BEGIN
T;
END
然后写procedureT
BEGIN
F;
M;
END
ProcedureF
BEGIN
+M;
END
ProcedureM
BEGIN
匹配a
END
这样的过程是递归下降的过程。递归下降方法仅表示一种思路,没有特别的
※LL(1)预测分析法:
第一个L表示从左到右扫描输入串
第二个L表示最左推导
1表示分析时每步只需向前查看一个符号
考虑First集和FOLLOW集:
First集,FIRST(α)是由α推导出的所有的第一个终结符号组成的集合
FOLLOW集:FOLLOW(A)是由所有句型中紧跟在A后面的终结符a组成的集合
引入FOLLOW集的意义是,在有空转换的文法里,有时候不能确定是否把这个非终结符变成空,这就要看看这个非终结符跟着的元素,是否有可能匹配下一个元素。如果能匹配,那么就可以把它变成空
※※预测分析表
例
文法:
各个非终结符的first集合:
关于follow集合我们只要考虑有可能变成空转换的非终结符:
根据FIRST集和FOLLOW集可以生成一张LL(1)文法的预测分析表:
预测分析表法的分析过程:
要以表格的形式,列出分析栈的变化,输入,和输出动作:
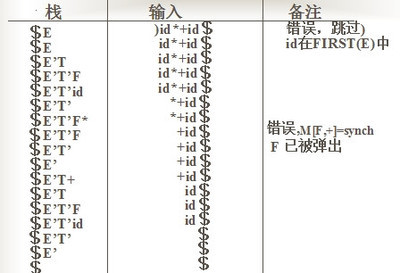
以下是上面的文法对于id+id*id串的分析过程
错误恢复:同步符号
有时候输入的串可能有点小错误掺杂了一些不该有的符号,可以利用同步符号synch跳过这些符号,使语法分析能够继续:
这就要考虑所有非终结符的FOLLOW集合:
以上面的文法的预测分析表做例子
FOLLOW集合:
加入错误处理的预测分析表:
串 )id+*id的分析过程: