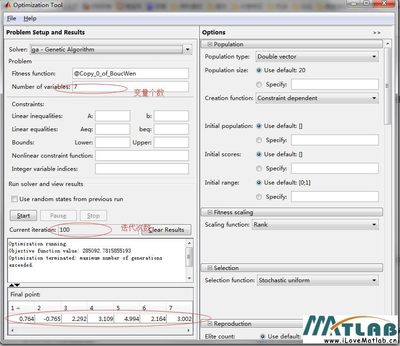
早上下雨了,淋了一身,且罢,浇浇脑子,全当施肥,不知清醒否。书还在昨天看到的地方,那就继续吧。
对最优化问题,求最优解或近似最优解的传统方法主要有解析法、随机法和穷举法。解析法主要包括爬山法和间接法。随机法主要包括导向随机方法和盲目随机方法。而穷举法主要包括完全穷举法、回溯法、动态规划法和限界剪枝法。
也可用遗传算法求解,遗传算法与传统方法有本质区别。传统算法起始于单个点,而遗传算法则起始于群体;传统算法是针对问题特有的特点进行改善,而遗传算法则是独立于问题。
具体区别如下:
1、遗传算法与启发式算法的比较:
启发式算法是指通过寻求一种能产生可行解的启发式规则,找到问题的一个最优解或近似最优解。然而它必须对每一个所求的问题找出其特有的启发式规则,且一般无通用性,不适用于其他问题。但遗传算法采用的不适确定性规则,而是强调利用概率转换来引导搜索过程。
2、遗传算法与爬山法的比较:
爬山法是指接法、梯度法和Hessian法的通称。首先在最优解可能存在的地方选择一个初始点,然后通过分析目标函数的特性,由初始点移到一个新的点,然后再继续这个过程。爬山法的搜索过程是确定的,它通过产生一系列的点收敛到最优解。而遗传算法的搜索过程是随机的,它产生一系列随机种群序列。二者的主要差异为:爬山法的初始点只有一个,由决策者给出;遗传算法的初始点有多个,是随机产生的。爬山法由一个点产生一个新的点;遗传算法通过遗传操作,在当前的种群中经过交叉、变异和选择产生下一代种群。
3、遗传算法与穷举法的比较:
穷举法就是对解空间内的所有可能解进行搜索,方法简单易行,但求解效率太低。而遗传算法则具有较高的搜索能力和极强的鲁棒性。
4、遗传算法与盲目随机法的比较:
只有解在搜索空间形成紧致分布时,盲目随机法才比较有效。而遗传算法作为导向随机搜索方法,是对一个被编码的参数空间进行高效搜索。
总结一下,主要有以下四点不同:
A、 遗传算法搜索种群中的点是并行的,而不是单点。
B、遗传算法并不需要辅助信息或辅助知识,只需要引进各项搜索方向的目标函数和相对应的适应度。
C、遗传算法使用概率变换规则,而不是确定的变换规则。
D、遗传算法工作使用编码参数集,而不是自身的参数集。(除了在实值个体中使用)
一些术语:
在遗传算法中,染色体对应的是数据或数组,在标准的遗传算法中,通常是由一维的串结构数据表现的。串上各个位置对应基因座,各位置上所取的值对应等位基因。遗传算法处理的是染色体或者叫基因型个体。一定数量的个体组成了群体,也叫集团。各个体对环境的适应程度叫适应度。
执行遗传算法时,包含两个必要的数据转换操作,一个是表现型到基因型的转换,它把搜索空间的参数或解转换成遗传空间中的染色体或个体,此过程称为编码操作;另一个是基因型到表现型的转换,它是前者的一个相反操作,称为译码操作。(对本项目而言,编码操作就是将各含能化合物设置成程序可以识别的二进制编码或其他代码,译码操作则是将生成的解转换成现实中的含能化合物结构或是分子式)
研究方向:
1、在遗传算法中,群体规模和遗传算子的控制参数的选取非常困难。存在过早收敛。
2、遗传算法的并行性主要有三个方面:个体适应度评价的并行性、整个群体各个个体适应度评价的并行性和子代群体产生过程的并行性。
3、分类系统属于基于遗传算法的机器学习中的一类,包括一个简单的基于串规则的并行生成子系统、规则评价子系统和遗传算法子系统。
4、遗传神经网络包括连接级、网络结构和学习规则的进化。
5、进化算法包括遗传算法、进化规划和进化策略,三种算法是独立发展起来的。
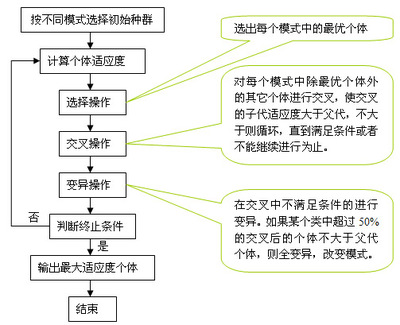
遗传算法的运行过程:
遗传算法模拟了自然选择和遗传中发生的复制、交叉和变异等现象,从任一初始种群(Population)出发,通过随机选择、交叉和变异操作,产生一群更适应环境的个体,使群体进化到搜索空间中越来越好的区域,这样一代一代地不断繁衍进化,最后收敛到一群最适应环境的个体(Individual),求得问题的最优解。
简单遗传算法的伪代码描述:
Procedure GA
Begin
T=0;
Initializep(t) ; //p(t)表示 t代种群
Evaluate p(t);//评估第t代种群
While not finished do
Begin
T=t+1;
Select p(t) from p(t-1);//从上代种群众选择较优秀的个体到下代子群
Reproduce pairs in p(t);
Evaluate p(t);
End
End
遗传算法的三个基本操作:
1、选择(Selection):根据各个个体的适应度值,按照一定的规则或方法从上一代群体中选择出一些优良的个体遗传到下一代群体中。体现了达尔文的适者生存原则。
2、交叉(Crossover):最主要的遗传操作。将群体中的各个个体随机搭配成对,对每一个个体,以某个概率(称为交叉概率,CrossoverRate)交换它们之间的部分染色体。体现了信息交换的思想。
3、变异(Mutation):对群体中的每一个个体,以某一概率(称为变异概率,MutationRate)改变某一个或某一些基因座上的基因值为其他的等位基因。
基本遗传算法(也称标准遗传算法或简单遗传算法,SimpleGeneticAlgorithm,简称SGA)是一种群体型操作,以群体中的所有个体为对象,只使用基本遗传算子:选择算子、交叉算子、变异算子。
基本遗传算法的步骤:
1、染色体编码:使用固定长度的二进制符号串来表示群体中的个体,其等位基因值由二值{0,1}组成。包括编码、解码公式。
2、个体适应度的监测评估:所有个体的适应度必须为非负数。需要预先确定好由目标函数值到个体适应度之间的转换规律,特别是要预先确定好当目标函数为负数时的处理方法。例如:可选取一个适当大的正数C,使个体的适应度为目标函数值加上正数C
3、 遗传算子:
(1)选择运算使用比例选择算子。比例选择因子是利用比例于各个个体适应度的概率决定其子孙的遗传可能性。
(2)交叉运算使用单点交叉算子。任意挑选经过选择操作中两个个体作为交叉对象,随机产生一个交叉点位置,两个个体在交叉点位置互换部分基因码,形成两个子个体。
(3)变异运算使用基本位变异算子或均匀变异算子。为了避免过早收敛,对于二进制的基因码组成的个体种群,实现基因码的小概率翻转,即0变为1,1变为0。
4、 基本遗传算法的运行参数:
(1)群体大小:一般取为20—100
(2)遗传算法的终止进化代数:一般取为100—500
(3)交叉概率:一般取为0.4—0.99
(4)变异概率:一般取为0.0001—0.1
看到现在,觉得问题最难的地方就是适应度和目标函数的确定,如何对数据进行编码,也没于头绪,是不是没吃早餐的原因,又犯困了,歇会。
遗传算法目前存在的问题:
1、适应度值标定方式多种多样,没有一个简洁、通用的方法,不利于对遗传算法的使用。
2、遗传算法的早熟现象(即很快收敛到局部最优解而不是全局最优解)是迄今为止最难处理的关键问题。
3、快要接近最优解时在最优解附近左右摆动,收敛较慢。
遗传算法通常需要解决以下问题:确定编码方案,使硬度函数标定,选择遗传操作方式,选择相关控制操作,停止准则确定等。(每个都得解决,不容易啊)
七种改进的遗传算法:
1、 分层遗传算法(Hierarchic GeneticAlgorithm)
2、 CHC算法
3、 Messy算法
4、 自适应遗传算法(Adaption GeneticAlgorithm)
5、 基于小生境技术的遗传算法(Niched GeneticAlgorithm,简称NGA)
6、 并行遗传算法(Parallel GeneticAlgorithm)
7、混合遗传算法:遗传算法与最速下降法相结合;遗传算法与模拟退火法(SimulatedAnnealing)相结合