上google搜索"JSTOR数据库国内",设置只显示最后一月的结果(要不就等着出来些不能用的死东西吧)出来些乱七八糟的结果,翻页到第4页面,发现某大学图书馆外网入口。
点击看看,结果令人大喜:这哥哥还把帐号密码贴出来了。
OK,直接上,输入帐号密码进入人家的图书馆。
选择JSTOR(图上没列出来),结果让人觉得很有希望。
再看看咱们现在用的是啥,嘿嘿,说明的确是用上了的。
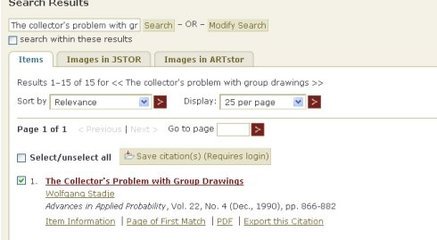
搜索感兴趣的内容,出结果:
点进去,可以看到内容啦,还可以翻页看第2第3页……,与刚才自己直接登陆的结果不同(看第一个图,不能翻页),这下子好了,可以翻页浏览了。
但是如何下载PDF?点击刚才搜索结果那里的"pdf"链接,出来的却是:
研究一下这图书馆的JSTOR和原版有啥不同:
看出来这图书馆给原版做了个rewriter,然后给不同数据库做了个处理,这里是对JSTOR做了处理,然后是使用http连接,然后表明地址是vvv9irsnq9nqf,大家把这字符ASCII都加1其实是www:jstor:org,可以看出来是指明了JSTOR的地址,OK,按照这个思路,我们觉得,刚才之所以出现404是因为相对路径问题,我们点击"pdf"后生成了个URL,此URL是相对此网站我的PDF全文相对地址,我们现在是在120.31.67.66上,因而生成了http://120.31.67.66/stable/pdfplus/XXX.pdf这链接,自然是404,我们应当去连http://www.jstor.org/stable/pdfplus/XXX.pdf才行嘛,当然,你直接连是不行的——因为人家不让你下载嘛,只好通过这图书馆连——我们可以看出,这图书馆做得不太好,显然他们自己人用的时候也不能方便地下载PDF的。根据此前经验,我们直接在vvv9irsnq9nqf后加上/stable/pdfplus/1427566.pdf各字符ASCII+1行么?结果不行,那就不加1,直接给它接过去,如下:
OK,可行,已拿到想要的论文了,记下来这一方法,以备后用,怕忘了。