Register)是CPU内部的元件,所以在寄存器之间的数据传送非常快。用途:1.可将寄存器内的数据执行算术及逻辑运算。2.存于寄存器内的地址可用来指向内存的某个位置,即寻址。3.可以用来读写数据到电脑的周边设备。8086 有8个8位数据寄存器,这些8位寄存器可分别组成16位寄存器:AH&AL=AX:累加寄存器,常用于运算;BH&BL=BX:基址寄存器,常用于地址索引;CH&CL=CX:计数寄存器,常用于计数;DH&DL=DX:数据寄存器,常用于数据传递。为了运用所有的内存空间,8086设定了四个段寄存器,专门用来保存段地址:CS(Code Segment):代码段寄存器;DS(Data Segment):数据段寄存器;SS(Stack Segment):堆栈段寄存器;ES(Extra Segment):附加段寄存器。当一个程序要执行时,就要决定程序代码、数据和堆栈各要用到内存的哪些位置,通过设定段寄存器 CS,DS,SS 来指向这些起始位置。通常是将DS固定,而根据需要修改CS。所以,程序可以在可寻址空间小于64K的情况下被写成任意大小。 所以,程序和其数据组合起来的大小,限制在DS 所指的64K内,这就是COM文件不得大于64K的原因。8086以内存做为战场,用寄存器做为军事基地,以加速工作。除了前面所提的寄存器外,还有一些特殊功能的寄存器:IP(Intruction Pointer):指令指针寄存器,与CS配合使用,可跟踪程序的执行过程;SP(Stack Pointer):堆栈指针,与SS配合使用,可指向目前的堆栈位置。BP(Base Pointer):基址指针寄存器,可用作SS的一个相对基址位置;SI(Source Index):源变址寄存器可用来存放相对于DS段之源变址指针;DI(Destination Index):目的变址寄存器,可用来存放相对于 ES 段之目的变址指针。还有一个标志寄存器FR(Flag Register),有九个有意义的标志(
OF: 溢出标志位OF用于反映有符号数加减运算所得结果是否溢出。如果运算结果超过当前运算位数所能表示的范围,则称为溢出,OF的值被置为1,否则,OF的值被清为0.
DF: 方向标志DF位用来决定在串操作指令执行时有关指针寄存器发生调整的方向。
IF: 中断允许标志IF位用来决定CPU是否响应CPU外部的可屏蔽中断发出的中断请求。但不管该标志为何值,CPU都必须响应CPU外部的不可屏蔽中断所发出的中断请求,以及CPU内部产生的中断请求。具体规定如下:
(1)、当IF=1时,CPU可以响应CPU外部的可屏蔽中断发出的中断请求;
(2)、当IF=0时,CPU不响应CPU外部的可屏蔽中断发出的中断请求。
TF: 状态控制标志位是用来控制CPU操作的,它们要通过专门的指令才能使之发生改变
SF: 符号标志SF用来反映运算结果的符号位,它与运算结果的最高位相同。在微机系统中,有符号数采用补码表示法,所以,SF也就反映运算结果的正负号。运算结果为正数时,SF的值为0,否则其值为1。
ZF: 零标志ZF用来反映运算结果是否为0。如果运算结果为0,则其值为1,否则其值为0。在判断运算结果是否为0时,可使用此标志位。
AF: 下列情况下,辅助进位标志AF的值被置为1,否则其值为0:
(1)、在字操作时,发生低字节向高字节进位或借位时;
(2)、在字节操作时,发生低4位向高4位进位或借位时。
PF: 奇偶标志PF用于反映运算结果中“1”的个数的奇偶性。如果“1”的个数为偶数,则PF的值为1,否则其值为0。
CF: 进位标志CF主要用来反映运算是否产生进位或借位。如果运算结果的最高位产生了一个进位或借位,那么,其值为1,否则其值为0。)
一、80x86系列CPU的编程结构
寄存器在汇编语言中的地位类似于变量。寄存器变量的访问时间远小于内存变量的访问时间。在汇编语言中大量的使用寄存器而不是直接访问内存。
1 寄存器堆
8086CPU是Intel系列的16位微处理器,有16根数据线和20根地址线,直接寻址空间为2^20即1MB。8088CPU的对外数据总线为8位,称为准16位微处理器。
8086/8088的内部寄存器(register)共有14个,如下:
(1)通用寄存器:8个,包括数据寄存器、地址指针寄存器、变址寄存器。
数据寄存器4个:AX BX CX DX,它们又可作为8个8位的寄存器使用,即AH BH CH DH AL BL CL DL
AX称为累加器,I/O指令均使用该寄存器,访问外部硬件和接口。
BX称为基址寄存器,在访问内存时用于存放基地址。
CX称为计数寄存器,用于循环、字符串的循环控制。
DX称为数据寄存器,在寄存器间接寻址的i/o指令中存放i/o地址,在作双字运算时[DX][AX]构成一个双字。
地址指针寄存器2个:SP BP
SP称为堆栈指针寄存器,BP称为基址指针寄存器,在作数组和字符串运算时,用于存放内存的偏移地址。
变址寄存器2个:SI DI
SI称为源变址寄存器,DI称为目的变址寄存器,用于数据块操作的内存寻址。
(2)段寄存器4个:CS DS ES SS
CS代码段寄存器,DS数据段寄存器,ES附加段寄存器,SS堆栈段寄存器
用于存放段地址(段基址)
(3)指令指针IP:始终指向将要执行的指令。用户不能直接访问和编程。
(4)标志寄存器FLAGS:16位寄存器,8086/8088仅使用了九个标志位。
2 标志寄存器
CF:进位标志位
PF:奇偶标志位
AF:辅助进位位
ZF:零标志位
SF:符号标志位
OF:溢出标志位
TF:跟踪标志位:单步标志
IF:中断标志位
DF:方向标志位
其中前六个为状态标志位,也叫条件码,用作条件转移指令中的判断条件。
后三个为控制标志位,对相关的操作起控制作用。
14个寄存器的内容,将要执行的指令,将要处理的数据,被称作CPU的“现场”,用debug的r命令可以清楚地看到“现场”。
二、内存的分段组织
计算机的基本存储单位是字节,由8个二进制位组成,8个位捆绑使用。可用一个两位16进制数表示其内容。16位CPU一次可以处理两个字节。
为了正确访问内存,每一个存储器单位即字节必须给出一个地址。地址编号从0开始,依次加1,被称为线性编址。
8086的地址线有20根,(详述)能够直接访问的地址空间为2^20即1MB。即内存的地址编号可以从0编到1M。用16进制数表示内存的物理地址,其地址范围为00000H~FFFFFH,为5位16进制数。每一个内存单元都有一个确定的20位物理地址。
但是,16位CPU的字长为16位,一次只能访问2^16=64k内存,如何访问1M的内存空间呢,在8086CPU中采用了地址分段的办法。即每一个存储单元的物理地址都有段地址和偏移地址两部分构成。
规定:(详述)只有地址为16的整数倍的物理地址可以作为段地址。这样,1MB的内存空间被分为了1M/16=64K个段。段地址的特征为xxxx0H。
我们知道了段地址和相对于段地址的段内偏移量(偏移地址)后就可以确定一个内存单元的物理地址了。所谓的偏移地址等于内存单元的物理地址减去段地址,不得超过一段(即64k)。
段地址可以不用20位表示,而用16位表示,即xxxx0H=xxxxH*10H表示为xxxxH,用4位16进制数表示。
物理地址的计算公式为:
物理地址=段地址*16+偏移地址
或者,物理地址=段地址*10H+偏移地址
乘以16相当于左移4位。即段地址左移4位和偏移地址相加。按十六进制数描述为,段地址左移一位和偏移地址相加。通常表示为
物理地址=段地址:偏移地址
例如:02002=0200:0002
可以看出,实际上偏移地址也是16位的,每一段的最大空间为2^16=64K,这样,不同的段之间有重叠。也即意味着物理地址可以有不同的表示方法。或者说不同的表示方法可以表示同一个物理地址。
例如:02020=0200:0020=0100:1020=0000:2020=0202:0000=......
举例说明:摩天大楼。
注意:实际上每个段并不一定占用64k的最大空间。
总结:如此麻烦的做法带来的好处是扩大了内存的表示空间,更重要的是,原本很麻烦的程序的再定位工作变得异常简单,实际上一般的程序员以及高级语言并不关心段地址,段地址的分配工作交给操作系统了。
在高级语言中,变量有两个含义:首先表示的是内存的偏移地址,对于占用两个以上存储单元的变量,其地址是低地址,一般为偶数。其次,表示存储的内容,对于字数据(两个字节),其高位存入高地址,低位存入低地址,如
xxxx:0200 2b ...var
xxxx:0201 01
xxxx:0202 00
xxxx:0203 01
对于整型变量 var,地址为0200,内容为01H*256+2BH=01H*100H+2BH=256+32+11
若为双字长整型变量var,则地址一般为4的整数倍。var的地址为0200,其内容为01H*1000000H+01H*100H+2BH=4096+256+32+11。
640K~1M 的内存称为 UMB (upper memory block)
它分为a000H,b000H,c000H,d000H,e000H,f000H六个段,f000H段为ROM。存放的是ROM-BIOS(加电自检程序、固化子程序库、硬件参数等)。
加电时,尽管主机板厂家可以不同,计算机总是从 ffff:0000开始运行,其中存放的总是jmp指令,指向加电自检程序(post)真正的起始处。
ffff段除了前16个内存单元(物理地址<<st1:chmetcnv tcsc="0" numbertype="1" negative="False" hasspace="False" sourcevalue="1" unitname="m" w:st="on">1M)外,还可以访问地址超过1M的部分内存,这部分内存称为HMA。
三、寻址方式(略)
取得操作数地址的方式称为寻址方式。
(1)数据寻址
立即寻址:mov al,5
寄存器寻址:mov ax,bx
直接寻址:mov ax,[2000H]
寄存器间接寻址:mov ax,[bx]
寄存器相对寻址:mov ax,offset[si]
基址变址寻址:mov ax,[bx][di]
相对基址变址寻址:mov offset[bx][si]
(2)指令寻址
段内直接寻址:jmp near ptr label1 //near ptr|short
段内间接寻址:jmp word ptr [offset][bp]
段间直接寻址:jmp far ptr label2
段间间接寻址:jmp dword ptr [offset][bx]
(3)端口寻址:
四、指令系统(略)
(一) 指令的执行时间
若时钟周期为T,则指令的基本执行时间如下(最佳寻址方式):
传送mov, 2T
加法add, 3T
整数乘法imul, 128T~154T
整数除法idiv, 165T~184T
移位(即乘以2或除以2), 2T
无条件转移, 15T
条件转移, 不转移 4T 转移 16T
采用不同方式寻址的加法指令执行时间如下:
寄存器到寄存器3T
存储器到寄存器9T+EA
寄存器到存储器16T+EA(访问两次存储器)
立即数到寄存器4T
立即数到存储器17T+EA(访问两次存储器)
不同寻址方式计算有效地址EA所需时间:
直接寻址 6T
寄存器间接寻址 5T
寄存器相对寻址 9T
基址寻址 7T~8T
相对基址变址寻址 11T~12T
总结:从指令执行时间上看,应尽量采用加法,避免乘法,尽量用移位不用乘法
尽量使用寄存器,少用存储器。尽量用简单的寻址方式,少用复杂的寻址方式。
(二) 指令系统
1.1 mov push pop xchg
1.2 in out xlat
1.3 lea lds les
1.4 lahf sahf pushf popf
注意:mov 等传送指令相当于赋值语句。in/out为基本的端口输入和输出
2.1 add adc inc
2.2 sub sbb dec neg cmp
2.3 mul imul
2.4 div idiv cbw cwd
2.5a daa das
2.5b aaa aas aam aad
3.1 and or not xor test
3.2 shl sal shr sal rol ror rcl rcr
4 movs cmps scas lods stos... ...rep repe|repz repne|repnz
5.1 jmp
5.2 jz|je jnz|jne js jns jo jno jp|jpe jnp|jpo jb|jnae|jc jnb|jae|jnc
... ...jb|jnae|jc jnb|jae|jnc jbe|jna jnbe|ja jl|jnge jnl|jge jle|jng jnle|jg
... ...jcxz
5.3 loop loopz|loope loopnz|loopne
5.4 call ret
5.5 int into iret
6.1 clc cmc stc cld std cli sti
6.2 nop hlt wait esc lock
五、汇编程序的格式
(1)汇编语言的语句种类与格式
1 指令语句
标号:指令助记符 操作数1,操作数2;注释
2 伪指令语句
名字 伪指令 参数1,参数2,...;注释
符号定义语句:equ =
数据块定义语句:db dw dd dq dt dup(?)
标号及其属性:
分析符type length size offset seg
标号类型label byte word dword near far
合成符ptr this
3 宏指令
4 段定义
segment ends
定位类型:para bye word page
组合类型:public common stack memory at
类别:code data stack
5 过程定义
proc endp
6 其他伪定义
assume org end
name title
even
radix
short high low
+ - * / mod
and or xor not
eq ne lt gt le ge
(2) com 文件格式(略)
code segment public 'code'
org 100H
assume cs:code,ds:data,es:data
main proc near
jmp start
message db 'How are u?$'
start:mov ah,9
mov dx,offse message
int 21H
int 20H
main endp
code ends
end main
(3) exe 文件格式(略)
stack segment stack 'stack'
db 256dup(?)
stack ends
data segment public 'data'
......
data ends
code segment public 'code'
assume cs:code,ds:data,es:data,ss:stack
main proc far
push ds ;保护psp前缀
xor ax,ax
push ax ;保护偏移0地址
mov ax,data
mov ds,ax
mov es,ax
......
ret
main endp
code ends
end main
x86系列的CPU是指最早由Intel公司生产的8086系列以及以后的后继产品,也包括了各CPU生产厂商仿制的产品。但不包括后来的各种形式的64位的CPU。
段是一个存储概念。
下面描述的主要是我的想象,你可以把它当成演义来看:),不必当真。
从8086 开始,Intel的CPU就已经是16位的了。所谓16位,是指它的数据总线,地址总线(注意,地址总线并不是如此的,后面会有详细的说明,事实上,它的地址总线是20位的),各个寄存器都是16位宽的。那真是一个简单的年代。16位地址总线意味着可以寻址64K的地址空间。甚至在那个年代,64K也有点小了。所以Intel决定(配合IBM的要求)采用20位地址总线。但这引发了一个问题,那就是:指令集如何设置?要知道,20位比16位多了4个位,这四个位放在何处?寄存器都是16位的!聪明的Intel的工程师开始想到了一个办法(我估计是受DEC的启发,它的CPU就是分段式的内存,不过, Intel的分段跟他还是有很大区别的,DEC的是不重叠的分段,而Intel的分段可以重叠),就是把地址空间分成两部分,一部分叫作段基址,一部分叫作段内地址。段内地址就是原始的16位地址,所以,段的大小最大是64K,那么段基址怎么办?我们知道,段基址要在20位的地址空间中(也就是1M的地址空间)表示一个地址,最合理的选择就是20位。但是,Intel的工程师当时认为,在一个16位的CPU中放置一个20位的寄存器不合情理,所以采用了一个聪明的偷懒办法。用一个16位的寄存器表达一个低4位为零的20位地址。说得明确一点,我用16进制表示,一个16位的寄存器,其值为NNNN,那么我们就把它看成NNNN0这样一个地址。这就是段基址寄存器。简单的叫做段寄存器。在我们想访问1M地址空间中的任意一个地址区域的时候,我们可以把段寄存器的值调整的靠近(所谓的靠近,也就是比这个地址空间小,但是不小于64K的某个地方)这个地址空间,然后通过段基址和段内地址之和,就可以访问1M内任意的地址空间了。修整段寄存器地址的这个动作叫作段切换。段内地址仍然是16位长,这也限制了段的长度是64K。看到这儿,你或许会想起些什么,或许会对所谓的近指针、远指针的概念有了一些回忆。哈哈。机制描述完了,我们开始看看这个设计引发的一些有趣的限制和问题。首先,段基址被限定为低4位为0,也就是NNNN0这种形式,那么,段基址一定是16的整数倍。呵呵,这个16被称作para(paragraph,段!注意,我们上面所描述的段被Intel 的工程师称为segment)。其次,由于FFFF0 + FFFF寻址的地址已经大于1M了(事实上,整整比1M大了一个segment的长度,64K),而实际上20位地址总线确实只能寻址1M的地址空间,这就说明了我们Intel工程师的这个设计其实没有达标!呵呵,确实没有想到会有这么一个问题。后来,应该是某个Intel的心理稍微有点变态的家伙说:我们让他回环吧。一开始,估计大家都觉得很失败,后来,大家都不禁被这个想法逗乐了,回环就这样被确定下来了。我说说回环是什么。很有意思。由于段基址+段内地址可以表达超过1M的地址空间,而地址总线只能寻址1M的地址空间,所以,所有超过1M地址空间的地址都减去1M。也就是说,所有大于1M的地址空间都重新从0开始计算,就好像又绕回来了一样。这就是回环。
8086CPU内部有5?个段寄存器。也就是说,同一时间我们可以维持5个段的存在。如果我们需要多于5个段的地址空间,段切换就行了。
这是段的缘起。
由于80186是失败的,而且可以到手的资料少得可怜,我就掠过去不说,80286问世了。她第一次引入了保护。我们想一下,由于我们可以把内存分段使用,所以似乎我们也可以简单的规定对某个段我们有什么可能的权利。比如:该段是TEXT段,只可以执行,或者该段是RDATA段,只能被读取什么的。所以,给最初的段机制加上保护似乎是顺理成章的事情。但是,286在加入保护这个问题上考虑的太少了,以至于其实是不完善的。
我们仔细的分析一下。由于段是在para的边界指定的。同时,只要在para的边界上,我们就可以指定一个段,再次强调,para是16。这说明:两个不同基址的段相差最少可以是 16。而段的最大长度却可以使64K。这回导致什么?这会导致段重叠。也就是说,一个真实的地址空间的地址,可以同时隶属于多个段。那么我们对它的保护是什么样子的?所有段的可访问性的总和?最小可访问性?没有什么定论。所以说,通过段进行存储空间的保护,在Intel的CPU上,学理不太通顺(我并不是要否定段保护,相反,完善的段保护机制非常有用,可惜,在x86的机器上行不通)。在x86的机器上,我们缺少了一些东西,一般认为,我们要加上段界限,同时禁止段重叠,才能真正的实施段保护。当然,286也确实实施了一定的保护,所以286的段切换要比8086代价高。原因自然是段切换需要切换的场景信息更多的缘故。
我上面的描述其实并不是事实,或者至少有一部分不是事实。那就是:286中的段寄存器存放的不再是简单的段基址了。它存放的是一个叫做段选择子的东西,这个东西指向存储空间中的段描述符表中的某一项,或者简单的说,指向段描述符。段描述符里面存放的才是真正的段基址什么的。用比较直白的术语,我们说它引入了一重间接性。
386出场了,看到别的CPU的寻址空间和OS都在飞速扩张,Intel终于搞出来一个32位的CPU出来。32位的地址空间逻辑上可以寻址4G的存储系统。简单的说,我们可以认为段内地址扩张成32位的了,但是段这个概念以及其实现方式跟286没有太大差别。386引入了一个页的概念,不过这与我们的主题无关。
我们说说OS方面的发展。由于地址空间扩大,而物理内存并没有同比例的扩大。(注:16 位扩展成32位,地址空间增加为原来的65536倍,就算从20位增加为32位,地址空间也增加了4096倍)。物理空间增加了大约500倍左右。这中间有一个巨大的差值。聪明的人们于是搞出来一个叫做虚拟内存的东西。希望能够尽量的使用地址空间。基本的策略就是用硬盘(或者别的外部存储设备)的一部分假装是内存。这样做有什么好处呢?这得从程序的特性说起,一个程序,不可能同时访问地址空间内所有的数据,而是相反,一段时间内集中在一个区域。这个特性叫做局部性。根据局部性,对于需要立即访问的放在物理内存中,不需要立即访问的放在虚拟内存中,等到需要访问时,再装入内存中以供访问。这简化了应用程序的逻辑,应用程序只需要按照自己的意图是用全部的地址空间就行了。这种物理内存和虚拟内存之间的倒腾由OS完成。实现虚拟内存需要CPU的支持(其实如果没有也行,不过性能根本就没办法保证),现在常用的甚至是唯一的方式就是内存分页,这个倒腾的过程也因而叫做换页。逻辑上,我们可以用分段来实现虚拟内存的(想想前面提到的段切换),但是由于段的不规整性(页的大小是一致的,规整的,而段不是,参见前面的描述),实现相对复杂,需要CPU的支持更多,性能更难以保证。所以,现代OS全都不约而同地采用分页的方式实现虚存,而没有采用分段的方式。
那么,对于x86这种既支持分段,有支持分页的CPU来说,OS究竟怎么办?其实,很简单,简单的忽略分段就行了。那位说了,这不是你想忽略就忽略的吧。x86CPU访问存储空间地址的时候就是采用段基址+段内地址的呀,这是硬件的实现,岂是我们可以忽略的?呵呵,如果我们把段基址规定成0怎么样?这样我们就可以不关心段了。是的,现代OS都是这样做的。
比如:Windows系统,其几个段寄存器(存放的是段选择子了)都是指向28(好像是)号段描述符,而28号段描述符都是0基址的。
持平的说,x86系列CPU的段机制设计的还算是比较好的,颇有巴洛克的味道,跟Intel第一次64位CPU的尝试安腾一样。呵呵。
上面所说的一切都是记忆,不提供任何正确性担保,聪明人都不会看它的,当然,看了的人更聪明。
为什么16位cpu地址总线要20根
在学习内存寻址的时候,大多数资料都写到:由于要满足8086的1M寻址空间,Intel的聪明的工程师想出了“段式”方法,来把1M空间分成64K段地址空间来管理,也就出现了所谓的段地址+段内偏移量来达到寻址的目的。这样的原因看起来很理所应当,而且的确非常漂亮。但是到了32位机器时代的来临,甚至64位的出现,这个架构始终面临着向后兼容的痛苦,要“兼容”这个段式寻址。
但我要提出的疑问是: 为什么当时会出现8086的1M的寻址空间呢?64K的地址空间就那么不够用么?非“逼着”大家想出来“段式”这么一个“可怕的”历史结果。不知道大家对于后面引起的实模式和保护模式
在经过“谷歌”以后,找到一个可以勉强解释的理由:
原文地址:http://blog.chinaunix.net/u/21948/showart_239664.html
“但当上升到16位机后,Intel8086/8088CPU的设计由于当年IC集成技术和外封装及引脚技术的限制,不能超过40个引脚。但又感觉到8位机原来的地址寻址能力2^16=64KB太少了,但直接增加到16的整数倍即令AB=32位又是达不到的。故而只能把AB暂时增加4条成为20条。则2^20=1MB的寻址能力已经增加了16倍。但此举却造成了AB的20位和DB的16位之间的矛盾,20位地址信息既无法在DB上传送,又无法在16位的CPU寄存器和内存单元中存放。于是应运而生就产生了CPU段结构的原理。”
这里有个理由看来是是合理的:40个引脚的限制。可以看到,AD0~AD15是分时复用的16条总线。这样就造成了期望在此基础上能够尽可能大的寻址,那么其中一条可选的也是很好的选择就是采用16位段寄存器+16位段内位移实现最大的且相对简单的寻址方式。
分段问题的产生:
x86系列的CPU是指最早由Intel公司生产的8086系列以及以后的后继产品,也包括了各CPU生产厂商仿制的产品。但不包括后来的各种形式的64位的CPU。
段是一个存储概念。
下面描述的主要是我的想象,你可以把它当成演义来看:),不必当真。
从8086 开始,Intel的CPU就已经是16位的了。所谓16位,是指它的数据总线,地址总线(注意,地址总线并不是如此的,后面会有详细的说明,事实上,它的地址总线是20位的),各个寄存器都是16位宽的。那真是一个简单的年代。16位地址总线意味着可以寻址64K的地址空间。甚至在那个年代,64K也有点小了。所以Intel决定(配合IBM的要求)采用20位地址总线。但这引发了一个问题,那就是:指令集如何设置?要知道,20位比16位多了4个位,这四个位放在何处?寄存器都是16位的!聪明的Intel的工程师开始想到了一个办法(我估计是受DEC的启发,它的CPU就是分段式的内存,不过,Intel的分段跟他还是有很大区别的,DEC的是不重叠的分段,而Intel的分段可以重叠),就是把地址空间分成两部分,一部分叫作段基址,一部分叫作段内地址。段内地址就是原始的16位地址,所以,段的大小最大是64K,那么段基址怎么办?我们知道,段基址要在20位的地址空间中(也就是1M的地址空间)表示一个地址,最合理的选择就是20位。但是,Intel的工程师当时认为,在一个16位的CPU中放置一个20位的寄存器不合情理,所以采用了一个聪明的偷懒办法。用一个16位的寄存器表达一个低4位为零的20位地址。说得明确一点,我用16进制表示,一个16位的寄存器,其值为NNNN,那么我们就把它看成NNNN0这样一个地址。这就是段基址寄存器。简单的叫做段寄存器。在我们想访问1M地址空间中的任意一个地址区域的时候,我们可以把段寄存器的值调整的靠近(所谓的靠近,也就是比这个地址空间小,但是不小于64K的某个地方)这个地址空间,然后通过段基址和段内地址之和,就可以访问1M内任意的地址空间了。修整段寄存器地址的这个动作叫作段切换。段内地址仍然是16位长,这也限制了段的长度是64K。看到这儿,你或许会想起些什么,或许会对所谓的近指针、远指针的概念有了一些回忆。哈哈。机制描述完了,我们开始看看这个设计引发的一些有趣的限制和问题。首先,段基址被限定为低4位为0,也就是NNNN0这种形式,那么,段基址一定是16的整数倍。呵呵,这个16被称作para(paragraph,段!注意,我们上面所描述的段被Intel 的工程师称为segment)。其次,由于FFFF0 + FFFF寻址的地址已经大于1M了(事实上,整整比1M大了一个segment的长度,64K),而实际上20位地址总线确实只能寻址1M的地址空间,这就说明了我们Intel工程师的这个设计其实没有达标!呵呵,确实没有想到会有这么一个问题。后来,应该是某个Intel的心理稍微有点变态的家伙说:我们让他回环吧。一开始,估计大家都觉得很失败,后来,大家都不禁被这个想法逗乐了,回环就这样被确定下来了。我说说回环是什么。很有意思。由于段基址+段内地址可以表达超过1M的地址空间,而地址总线只能寻址1M的地址空间,所以,所有超过1M地址空间的地址都减去1M。也就是说,所有大于1M的地址空间都重新从0开始计算,就好像又绕回来了一样。这就是回环。
8086CPU内部有5?个段寄存器。也就是说,同一时间我们可以维持5个段的存在。如果我们需要多于5个段的地址空间,段切换就行了。
这是段的缘起。
由于80186是失败的,而且可以到手的资料少得可怜,我就掠过去不说,80286问世了。她第一次引入了保护。我们想一下,由于我们可以把内存分段使用,所以似乎我们也可以简单的规定对某个段我们有什么可能的权利。比如:该段是TEXT段,只可以执行,或者该段是RDATA段,只能被读取什么的。所以,给最初的段机制加上保护似乎是顺理成章的事情。但是,286在加入保护这个问题上考虑的太少了,以至于其实是不完善的。
我们仔细的分析一下。由于段是在para的边界指定的。同时,只要在para的边界上,我们就可以指定一个段,再次强调,para是16。这说明:两个不同基址的段相差最少可以是16。而段的最大长度却可以使64K。这回导致什么?这会导致段重叠。也就是说,一个真实的地址空间的地址,可以同时隶属于多个段。那么我们对它的保护是什么样子的?所有段的可访问性的总和?最小可访问性?没有什么定论。所以说,通过段进行存储空间的保护,在Intel的CPU上,学理不太通顺(我并不是要否定段保护,相反,完善的段保护机制非常有用,可惜,在x86的机器上行不通)。在x86的机器上,我们缺少了一些东西,一般认为,我们要加上段界限,同时禁止段重叠,才能真正的实施段保护。当然,286也确实实施了一定的保护,所以286的段切换要比8086代价高。原因自然是段切换需要切换的场景信息更多的缘故。
我上面的描述其实并不是事实,或者至少有一部分不是事实。那就是:286中的段寄存器存放的不再是简单的段基址了。它存放的是一个叫做段选择子的东西,这个东西指向存储空间中的段描述符表中的某一项,或者简单的说,指向段描述符。段描述符里面存放的才是真正的段基址什么的。用比较直白的术语,我们说它引入了一重间接性。
386出场了,看到别的CPU的寻址空间和OS都在飞速扩张,Intel终于搞出来一个32位的CPU出来。32位的地址空间逻辑上可以寻址4G的存储系统。简单的说,我们可以认为段内地址扩张成32位的了,但是段这个概念以及其实现方式跟286没有太大差别。386引入了一个页的概念,不过这与我们的主题无关。
我们说说OS方面的发展。由于地址空间扩大,而物理内存并没有同比例的扩大。(注:16 位扩展成32位,地址空间增加为原来的65536倍,就算从20位增加为32位,地址空间也增加了4096倍)。物理空间增加了大约500倍左右。这中间有一个巨大的差值。聪明的人们于是搞出来一个叫做虚拟内存的东西。希望能够尽量的使用地址空间。基本的策略就是用硬盘(或者别的外部存储设备)的一部分假装是内存。这样做有什么好处呢?这得从程序的特性说起,一个程序,不可能同时访问地址空间内所有的数据,而是相反,一段时间内集中在一个区域。这个特性叫做局部性。根据局部性,对于需要立即访问的放在物理内存中,不需要立即访问的放在虚拟内存中,等到需要访问时,再装入内存中以供访问。这简化了应用程序的逻辑,应用程序只需要按照自己的意图是用全部的地址空间就行了。这种物理内存和虚拟内存之间的倒腾由OS完成。实现虚拟内存需要CPU的支持(其实如果没有也行,不过性能根本就没办法保证),现在常用的甚至是唯一的方式就是内存分页,这个倒腾的过程也因而叫做换页。逻辑上,我们可以用分段来实现虚拟内存的(想想前面提到的段切换),但是由于段的不规整性(页的大小是一致的,规整的,而段不是,参见前面的描述),实现相对复杂,需要CPU的支持更多,性能更难以保证。所以,现代OS全都不约而同地采用分页的方式实现虚存,而没有采用分段的方式。
那么,对于x86这种既支持分段,有支持分页的CPU来说,OS究竟怎么办?其实,很简单,简单的忽略分段就行了。那位说了,这不是你想忽略就忽略的吧。x86CPU访问存储空间地址的时候就是采用段基址+段内地址的呀,这是硬件的实现,岂是我们可以忽略的?呵呵,如果我们把段基址规定成0怎么样?这样我们就可以不关心段了。是的,现代OS都是这样做的。
比如:Windows系统,其几个段寄存器(存放的是段选择子了)都是指向28(好像是)号段描述符,而28号段描述符都是0基址的。
持平的说,x86系列CPU的段机制设计的还算是比较好的,颇有巴洛克的味道,跟Intel第一次64位CPU的尝试安腾一样。呵呵。
上面所说的一切都是记忆,不提供任何正确性担保,聪明人都不会看它的,当然,看了的人更聪明。
学习Linux内核也好,进行嵌入式系统移植也好,免不了要跟内存打交道。要和内存打交道,那就免不了和内存单元的“门牌号”地址打交道。以前没有系统地整理过,看到16页,发现自己对地址的概念并不是非常清晰,所以从网上搜集了一些资料,经过思考,现在整理如下。
每个存储单元在存储器中的位置可以用逻辑地址和物理地址来表示。
(1)逻辑地址(Logical Address)是由段基址和段内偏移地址两部分组成。以8051单片机为例,段基址和段内偏移地址都是无符号的16位二进制数。
(2)物理地址(Physical Address)也叫实际地址或绝对地址,是出现在CPU外部地址总线上的寻址物理内存的地址信号,是地址变换的最终结果。
(3)线性地址(Linear Address)是逻辑地址到物理地址变换之间的中间层。程序代码会产生逻辑地址,通过逻辑地址变换就可以生成一个线性地址。如果启用了分页机制,那么线性地址可以再经过变换以产生一个物理地址。如果没有启用分页机制,那么线性地址直接就是物理地址。
由此看出,逻辑地址不等于物理地址。所谓的物理地址,就是实实在在的通过CPU外部地址总线的地址信号。不管采取什么地址映射机制,最终要得到的就是物理地址。
下面给出两份资料,对理解有很大帮助。
材料一:8086/8088CPU为什么要采用段结构?
我们研究科学、要知其然,更要知其所以然。要多问几个为什么;看问题的方法要“扒皮抽筋,入骨三分”的。这里我们就要问一问,8086/8088CPU为什么采用段结构,其原理是什么?
追根求源,Intel的8位机8080CPU,数据总线DB为8位,地址总线为16位。那么这个16位地址信息也是要通过8位数据总线来传送,也是要在数据通道中的暂存器,以及在CPU中的寄存器和内存中存放的,但由于AB正好是DB的整数倍,故不会产生矛盾!
但当上升到16位机后,Intel8086/8088CPU的设计由于当年IC集成技术和外封装及引脚技术的限制,不能超过40个引脚。但又感觉到8位机原来的地址寻址能力2^16=64KB太少了,但直接增加到16的整数倍即令AB=32位又是达不到的。故而只能把AB暂时增加4条成为20条。则2^20=1MB的寻址能力已经增加了16倍。但此举却造成了AB的20位和DB的16位之间的矛盾,20位地址信息既无法在DB上传送,又无法在16位的CPU寄存器和内存单元中存放。于是应运而生就产生了CPU段结构的原理。
首先我们要把教学的“有效数字”的概念应用到20位二进制物理地址中,有效数字位的数字可为1,也可为0,我们现在要把20位有效数字的物理地址分成两段,可以有多种分法。但要求这两段分开后,每段不能大于16位,也不能小于4位。共有13种分法,形成的高位有效数字可为nbits(n=4,5,6,...,16),低位有效数字等于(20-n)bits。高位有效数字即为段首址,但要在其低位补上无效数字的零,仍然保持20位。然后右移四位,把低四位无效的零自然丢失,形成逻辑地址的十六位段首址。20位实际地址中,低位有效数字即为段内偏移量,当不足16位时要在其高位补上若干无效的零,形成逻辑地址的十六位段内偏移量。
下面我们来分析一个这个由段首址和段内偏移量两部分构成的逻辑地址的性质:
性质一:如上所述形成的段首址和段内偏移量均为十六位,可以很方便的在数据总线上传送,及在CPU寄存器和内存单元中存放。
性质二:段首址即该段的内存首地址。段内偏移量则是该段的范围内距离段首址的字节数。
性质三:因为段首址的有效数字和段内偏移量有效数字是互补的,所以段的大小可以说是由段首址的有效数字决定,也可以说是由段内偏移量有效数字的长短决定。即段的取值范围是段内偏移量有效数字的长度从全0,然而末位加一,直至全一。
性质四:段的大小则可以是2^4、2^5、2^6……2^16即16,32,64……64K个字节。共有十三种大小不同的段可供选择。
性质五:当需要对内存寻址时,只须将段首址送入20位地址加法器中,然后左移四位,并且末位补上四个零,而后加上段内偏移量即可送到20位地址总线上。由此才将段首址和段内偏移量决定的逻辑地址变成20位物理地址!
性质六:请注意,这里的“加法”不是一般教材中所讲的“叠加”,段首址的有效数字和段内偏移量的有效数字位是不能重叠的!二者只能是高低有效数字的“衔接”,只有如此才能复原20位物理地址的本来面目。否则,将会改变段首址的取值,超越该段的取值范围,而且也破坏了20位物理地址的本来面目。这才是段结构原理的真谛!
材料二:
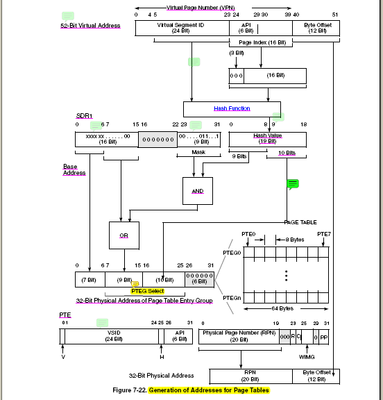
题目:在分页存储管理中,须将逻辑地址转换成物理地址,在分页地址转换中,地址字长16位,页长4KB,现有一逻辑地址字为2F6AH,则其相应物理地址为______.页表如下:
页号 块号
0 5
1 10
2 11
【解析】
逻辑地址=页号+页内地址
物理地址=块号+块内地址
页内地址=块内地址
此题中页长4KB,即2^12,所以页内地址占了16位地址字长的低12位。由此确定所求页内地址为0F6AH,相应的页号为2。通过页表得知,页号2对应块号11,而11=BH。所以相应的物理地址为BF6AH。可以认为这里的2F6AH为线性地址,再次变换得到物理地址BF6AH。