发一份自编的MATLAB遗传算法代码,用简单遗传算法(Simple Genetic Algorithm or StandardGeneticAlgorithm,SGA)求取函数最大值,初版编写于7年前上学期间,当时是MATLAB5.x,稍微做了修改。
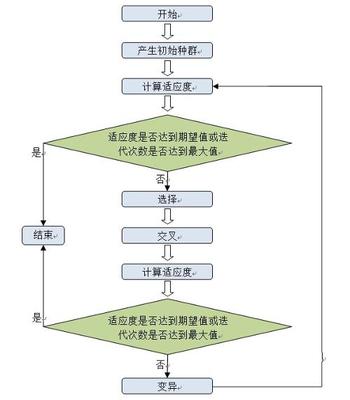
遗传算法为群体优化算法,也就是从多个初始解开始进行优化,每个解称为一个染色体,各染色体之间通过竞争、合作、单独变异,不断进化。
优化时先要将实际问题转换到遗传空间,就是把实际问题的解用染色体表示,称为编码,反过程为解码,因为优化后要进行评价,所以要返回问题空间,故要进行解码。SGA采用二进制编码,染色体就是二进制位串,每一位可称为一个基因;如果直接生成二进制初始种群,则不必有编码过程,但要求解码时将染色体解码到问题可行域内。
遗传算法模拟“适者生存,优胜劣汰”的进化机制,染色体适应生存环境的能力用适应度函数衡量。对于优化问题,适应度函数由目标函数变换而来。一般遗传算法求解最大值问题,如果是最小值问题,则通过取倒数或者加负号处理。SGA要求适应度函数>0,对于<0的问题,要通过加一个足够大的正数来解决。这样,适应度函数值大的染色体生存能力强。
遗传算法有三个进化算子:选择(复制)、交叉和变异。
SGA中,选择采用轮盘赌方法,也就是将染色体分布在一个圆盘上,每个染色体占据一定的扇形区域,扇形区域的面积大小和染色体的适应度大小成正比。如果轮盘中心装一个可以转动的指针的话,旋转指针,指针停下来时会指向某一个区域,则该区域对应的染色体被选中。显然适应度高的染色体由于所占的扇形区域大,因此被选中的几率高,可能被选中多次,而适应度低的可能一次也选不中,从而被淘汰。算法实现时采用随机数方法,先将每个染色体的适应度除以所有染色体适应度的和,再累加,使他们根据适应度的大小分布于0-1之间,适应度大的占的区域大,然后随机生成一个0-1之间的随机数,随机数落到哪个区域,对应的染色体就被选中。重复操作,选出群体规模规定数目的染色体。这个操作就是“优胜劣汰,适者生存”,但没有产生新个体。
交叉模拟有性繁殖,由两个染色体共同作用产生后代,SGA采用单点交叉。由于SGA为二进制编码,所以染色体为二进制位串,随机生成一个小于位串长度的随机整数,交换两个染色体该点后的那部分位串。参与交叉的染色体是轮盘赌选出来的个体,并且还要根据选择概率来确定是否进行交叉(生成0-1之间随机数,看随机数是否小于规定的交叉概率),否则直接进入变异操作。这个操作是产生新个体的主要方法,不过基因都来自父辈个体。
变异采用位点变异,对于二进制位串,0变为1,1变为0就是变异。采用概率确定变异位,对每一位生成一个0-1之间的随机数,看是否小于规定的变异概率,小于的变异,否则保持原状。这个操作能够使个体不同于父辈而具有自己独立的特征基因,主要用于跳出局部极值。
遗传算法认为生物由低级到高级进化,后代比前一代强,但实际操作中可能有退化现象,所以采用最佳个体保留法,也就是曾经出现的最好个体,一定要保证生存下来,使后代至少不差于前一代。
下面为代码。函数最大值为3905.9262,此时两个参数均为-2.0480,有时会出现局部极值,此时一个参数为-2.0480,一个为2.0480。变异概率pm=0.05,交叉概率pc=0.8。
(注:一位网名为mosquitee的朋友提醒我:原代码的变异点位置有问题。检验后发现是将最初的循环实现方法改为矩阵实现方法时为了最优去掉mm的第N行所致,导致变异点位置发生了变化,现做了修改,修改部分加了颜色标记,非常感谢mosquitee,2010-4-22)
% Optimizing a function using Simple GeneticAlgorithm with elitist preserved
%Max f(x1,x2)=100*(x1*x1-x2).^2+(1-x1).^2;-2.0480<=x1,x2<=2.0480
% Author: Wang Yonglin (wylin77@126.com)
clc;clear all;
format long;%设定数据显示格式
%初始化参数
T=100;%仿真代数
N=80;% 群体规模
pm=0.05;pc=0.8;%交叉变异概率
umax=2.048;umin=-2.048;%参数取值范围
L=10;%单个参数字串长度,总编码长度2L
bval=round(rand(N,2*L));%初始种群
bestv=-inf;%最优适应度初值
%迭代开始
for ii=1:T
%解码,计算适应度
for i=1:N
y1=0;y2=0;
for j=1:1:L
y1=y1+bval(i,L-j+1)*2^(j-1);
end
x1=(umax-umin)*y1/(2^L-1)+umin;
for j=1:1:L
y2=y2+bval(i,2*L-j+1)*2^(j-1);
end
x2=(umax-umin)*y2/(2^L-1)+umin;
obj(i)=100*(x1*x1-x2).^2+(1-x1).^2; %目标函数
xx(i,:)=[x1,x2];
end
func=obj;%目标函数转换为适应度函数
p=func./sum(func);
q=cumsum(p);%累加
[fmax,indmax]=max(func);%求当代最佳个体
if fmax>=bestv
bestv=fmax;%到目前为止最优适应度值
bvalxx=bval(indmax,:);%到目前为止最佳位串
optxx=xx(indmax,:);%到目前为止最优参数
end
Bfit1(ii)=bestv; %存储每代的最优适应度
%%%%遗传操作开始
%轮盘赌选择
for i=1:(N-1)
r=rand;
tmp=find(r<=q);
newbval(i,:)=bval(tmp(1),:);
end
newbval(N,:)=bvalxx;%最优保留
bval=newbval;
%单点交叉
for i=1:2:(N-1)
cc=rand;
if cc
point=ceil(rand*(2*L-1));%取得一个1到2L-1的整数
ch=bval(i,:);
bval(i,point+1:2*L)=bval(i+1,point+1:2*L);
bval(i+1,point+1:2*L)=ch(1,point+1:2*L);
end
end
bval(N,:)=bvalxx;%最优保留
%位点变异
mm=rand(N,2*L)
mm(N,:)=zeros(1,2*L);%最后一行不变异,强制赋0
bval(mm)=1-bval(mm);
end
%输出
plot(Bfit1);% 绘制最优适应度进化曲线
bestv %输出最优适应度值
optxx%输出最优参数




