最初的unicode编码是固定长度的,16位,也就是2两个字节代表一个字符,这样一共可以表示65536个字符。显然,这样要表示各种语言中所有的字符是远远不够的。Unicode4.0规范考虑到了这种情况,定义了一组附加字符编码,附加字符编码采用2个16位来表示,这样最多可以定义1048576个附加字符,目前unicode4.0只定义了45960个附加字符。
Unicode只是一个编码规范,目前实际实现的unicode编码只要有三种:UTF-8,UCS-2和UTF-16,三种unicode字符集之间可以按照规范进行转换。
UTF-8
UTF-8是一种8位的unicode字符集,编码长度是可变的,并且是ASCII字符集的严格超集,也就是说ASCII中每个字符的编码在UTF-8中是完全一样的。UTF-8字符集中,一个字符可能是1个字节,2个字节,3个字节或者4个字节长。一般来说,欧洲的字母字符长度为1到2个字节,而亚洲的大部分字符则是3个字节,附加字符为4个字节长。
Unix平台中普遍支持UTF-8字符集,HTML和大多数浏览器也支持UTF-8,而window和java则支持UCS-2。
UTF-8的主要优点:
UCS-2
UCS-2是固定长度为16位的unicode字符集。每个字符都是2个字节,UCS-2只支持unicode3.0,所以不支持附加字符。
UCS-2的优点:
UTF-16
UTF-16也是一种16位编码的字符集。实际上,UTF-16就是UCS-2加上附加字符的支持,也就是符合unicode4.0规范的UCS-2。所以UTF-16是UCS-2的严格超集。
UTF-16中的字符,要么是2个字节,要么是4个字节表示的。UTF-16主要在windows2000以上版本使用。
UTF-16相对UTF-8的优点,和UCS-2是一致的。
Oracle从7.0开始提供对Unicode的支持。Oracle个版本的unicode字符集支主要有:
AL32UTF8
一种UTF-8编码的字符集,支持最新的unicode4.0标准。字符长度为1,2或者3个字节,附加字符则为4字节长。
UTF8
支持unicode3.0的UTF-8编码方式。由于附加字符是在unicode3.1中提出的,UTF8不支持附加字符。但是unicode3.0已经为附加字符预留了编码空间,所以即使在UTF8的数据库中插入附加字符,也是可以的,只是数据库会将该字符分隔成两部分,需要占6个字符的长度。所以,如果需要支持附加字符,那么建议将数据库的字符集切换为新的AL32UTF8。
UTF8可用于数据库字符集,也可用于国家字符集。
UTFE
UTFE是基于EBCDIC平台的unicode字符集,就像ASCII平台上的UTF8一样。不同的是,UTFE中,每个字符可能占1,2,3或者4个字节,而附加字符则需要2个4个字节,也就是8个字节来表示。
AL16UTF16
AL16UTF16是一种UTF-16编码的unicode字符集,在Oracle中用于国家字符集。
AL24UTFFSS
该字符集只支持unicode1.1规范,在Oracle7.2~8i版本中使用,目前已经淘汰。
CString在Unicode下一个字节占16bit,在ascii下占8bit,改成char数组后在什么环境下都一样的
编写程序最好是:同一个源文件既可以在UNICODE下编译,又可以在ANSI下编译
工程--设置--C/C++--预处理器,可以定义标识符,如UNICODE,_UNICODE,标识是按ASCII编译,还是按UNICODE编译
#include <tchar.h>
char定义全部 改成 TCHAR,TCHAR根据设置不同定义为char或者wchar
字符串加用TEXT宏,如TEXT("你好"),根据编译器的设置不同,分别定义为ANSI或者UNICODE版本
字符串也大部分有其通用版本:
最大长度版比标准版多一个参数,表示缓冲区的长度
有v的其参数为参数列表指针,使用va_list、va_start和va_end宏
C提供的字符串函数: ASCII 宽字符 通用形式
1.可变参数:
标准版 sprintf swprintf _stprintf
最大长度版 _snprintf _snwprintf _sntprintf
WindowsNT版 wsprintfA wsprintfW wsprintf
2.数组的指针作参数:
标准版 vsprintf vswprintf _vstprintf
最大长度版 _vsnprintf _vsnwprintf _vsntprintf
WindowsNT版 wvsprintfA wvsprintfW wvsprintf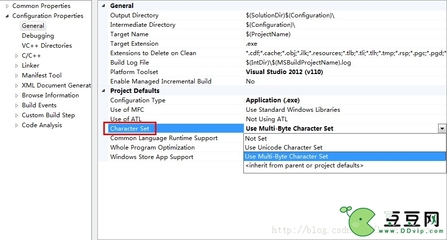
以下引用《Windows程序设计》
美国标准
早期计算机的字符码是从Hollerith卡片(号称不能被折迭、卷曲或毁伤)发展而来的,该卡片由HermanHollerith发明并首次在1890年的美国人口普查中使用。6位字符码系统BCDIC(Binary-Coded DecimalInterchangeCode:二进制编码十进制交换编码)源自Hollerith代码,在60年代逐步扩展为8位EBCDIC,并一直是IBM大型主机的标准,但没使用在其它地方。
美国信息交换标准码(ASCII:American Standard Code for InformationInterchange)起始于50年代后期,最后完成于1967年。开发ASCII的过程中,在字符长度是6位、7位还是8位的问题上产生了很大的争议。从可靠性的观点来看不应使用替换字符,因此ASCII不能是6位编码,但由于费用的原因也排除了8位版本的方案(当时每位的储存空间成本仍很昂贵)。这样,最终的字符码就有26个小写字母、26个大写字母、10个数字、32个符号、33个句柄和一个空格,总共128个字符码。ASCII现在记录在ANSIX3.4-1986字符集-用于信息交换的7位美国国家标准码(7-Bit ASCII:7-Bit American NationalStandard Code for Information Interchange),由美国国家标准协会(AmericanNational StandardsInstitute)发布。图2-1中所示的ASCII字符码与ANSI文件中的格式相似。
ASCII有许多优点。例如,26个字母代码是连续的(在EBCDIC代码中就不是这样的);大写字母和小写字母可通过改变一位数据而相互转化;10个数字的代码可从数值本身方便地得到(在BCDIC代码中,字符「0」的编码在字符「9」的后面!)
最棒的是,ASCII是一个非常可靠的标准。在键盘、视讯显示卡、系统硬件、打印机、字体文件、操作系统和Internet上,其它标准都不如ASCII码流行而且根深蒂固。
图2-1 ASCII字符集
国际方面
ASCII的最大问题就是该缩写的第一个字母。ASCII是一个真正的美国标准,所以它不能良好满足其它讲英语国家的需要。例如英国的英镑符号(£)在哪里?
英语使用拉丁(或罗马)字母表。在使用拉丁语字母表的书写语言中,英语中的单词通常很少需要重音符号(或读音符号)。即使那些传统惯例加上读音符号也无不当的英语单字,例如c鰋perate或者résumé,拼写中没有读音符号也会被完全接受。
但在美国以南、以北,以及大西洋地区的许多国家,在语言中使用读音符号很普遍。这些重音符号最初是为使拉丁字母表适合这些语言读音不同的需要。在远东或西欧的南部旅游,您会遇到根本不使用拉丁字母的语言,例如希腊语、希伯来语、阿拉伯语和俄语(使用斯拉夫字母表)。如果您向东走得更远,就会发现中国象形汉字,日本和朝鲜也采用汉字系统。
ASCII的历史开始于1967年,此后它主要致力于克服其自身限制以更适合于非美国英语的其它语言。例如,1967年,国际标准化组织(ISO:InternationalStandardsOrganization)推荐一个ASCII的变种,代码0x40、0x5B、0x5C、0x5D、0x7B、0x7C和0x7D「为国家使用保留」,而代码0x5E、0x60和0x7E标为「当国内要求的特殊字符需要8、9或10个空间位置时,可用于其它图形符号」。这显然不是一个最佳的国际解决方案,因为这并不能保证一致性。但这却显示了人们如何想尽办法为不同的语言来编码的。
扩展ASCII
在小型计算机开发的初期,就已经严格地建立了8位字节。因此,如果使用一个字节来保存字符,则需要128个附加的字符来补充ASCII。1981年,当最初的IBMPC推出时,视讯卡的ROM中烧有一个提供256个字符的字符集,这也成为IBM标准的一个重要组成部分。
最初的IBM扩展字符集包括某些带重音的字符和一个小写希腊字母表(在数学符号中非常有用),还包括一些块型和线状图形字符。附加的字符也被添加到ASCII控制字符的编码位置,这是因为大多数控制字符都不是拿来显示用的。
该IBM扩展字符集被烧进无数显示卡和打印机的ROM中,并被许多应用程序用于修饰其文字模式的显示方式。不过,该字符集并没有为所有使用拉丁字母表的西欧语言提供足够多的带重音字符,而且也不适用于Windows。Windows不需要图形字符,因为它有一个完全图形化的系统。
在Windows1.0(1985年11月发行)中,Microsoft没有完全放弃IBM扩展字符集,但它已退居第二重要位置。因为遵循了ANSI草案和ISO标准,纯Windows字符集被称作「ANSI字符集」。ANSI草案和ISO标准最终成为ANSI/ISO8859-1-1987,即「American National Standard for InformationProcessing-8-Bit Single-Byte Coded Graphic Character Sets-Part 1:Latin Alphabet No 1」,通常也简写为「Latin 1」。
在Windows 1.0的《Programmer'sReference》中印出了ANSI字符集的最初版本,如图2-2所示。
图2-2 Windows ANSI字符集(基于ANSI/ISO 8859-1)
空方框表示该位置未定义字符。这与ANSI/ISO 8859-1的最终定义一致。ANSI/ISO8859-1仅显示了图形字符,而没有控制字符,因此没有定义DEL。此外,代码0xA0定义为一个非断开的空格(这意味着在编排格式时,该字符不用于断开一行),代码0xAD是一个软连字符(表示除非在行尾断开单词时使用,否则不显示)。此外,ANSI/ISO8859-1将代码0xD7定义为乘号(*),0xF7为除号(/)。Windows中的某些字体也定义了从0x80到0x9F的某些字符,但这些不是ANSI/ISO8859-1标准的一部分。
MS-DOS 3.3(1987年4月发行)向IBM PC用户引进了代码页(codepage)的概念,Windows也使用此概念。代码页定义了字符的映像代码。最初的IBM字符集被称作代码页437,或者「MS-DOSLatin US)。代码页850就是「MS-DOS Latin 1」,它用附加的带重音字母(但不是图2-2所示的Latin 1ISO/ANSI标准)代替了一些线形字符。其它代码页被其它语言定义。最低的128个代码总是相同的;较高的128个代码取决于定义代码页的语言。
在MS-DOS中,如果用户为PC的键盘、显示卡和打印机指定了一个代码页,然后在PC上创建、编辑和打印文件,一切都很正常,每件事都会保持一致。然而,如果用户试图与使用不同代码页的用户交换文件,或者在机器上改变代码页,就会产生问题。字符码与错误的字符相关联。应用程序能够将代码页信息与文件一起保存来试图减少问题的产生,但该策略包括了某些在代码页间转换的工作。
虽然代码页最初仅提供了不包括带重音符号字母的附加拉丁字符集,但最终代码页的较高的128个字符还是包括了完整的非拉丁字母,例如希伯来语、希腊语和斯拉夫语。自然,如此多样会导致代码页变得混乱;如果少数带重音的字母未正确显示,那么整个文字便会混乱不堪而不可阅读。
代码页的扩展正是基于所有这些原因,但是还不够。斯拉夫语的MS-DOS代码页855与斯拉夫语的Windows代码页1251以及斯拉夫语的Macintosh代码页10007不同。每个环境下的代码页都是对该环境所作的标准字符集修正。IBMOS/2也支援多种EBCDIC代码页。
但等一下,你会发现事情变得更糟糕。
双字节字符集
迄今为止,我们已经看到了256个字符的字符集。但中国、日本和韩国的象形文字符号有大约21,000个。如何容纳这些语言而仍保持和ASCII的某种兼容性呢?
解决方案(如果这个说法正确的话)是双字节字符集(DBCS:double-byte characterset)。DBCS从256代码开始,就像ASCII一样。与任何行为良好的代码页一样,最初的128个代码是ASCII。然而,较高的128个代码中的某些总是跟随着第二个字节。这两个字节一起(称作首字节和跟随字节)定义一个字符,通常是一个复杂的象形文字。
虽然中文、日文和韩文共享一些相同的象形文字,但显然这三种语言是不同的,而且经常是同一个象形文字在三种不同的语言中代表三件不同的事。Windows支持四个不同的双字节字符集:代码页932(日文)、936(简体中文)、949(韩语)和950(繁体汉字)。只有为这些国家(地区)生产的Windows版本才支持DBCS。
双字符集问题并不是说字符由两个字节代表。问题在于一些字符(特别是ASCII字符)由1个字节表示。这会引起附加的程序设计问题。例如,字符串中的字符数不能由字符串的字节数决定。必须剖析字符串来决定其长度,而且必须检查每个字节以确定它是否为双字节字符的首字节。如果有一个指向DBCS字符串中间的指针,那么该字符串前一个字符的地址是什么呢?惯用的解决方案是从开始的指针分析该字符串!
Unicode解决方案
我们面临的基本问题是世界上的书写语言不能简单地用256个8位代码表示。以前的解决方案包括代码页和DBCS已被证明是不能满足需要的,而且也是笨拙的。那什么才是真正的解决方案呢?
身为程序写作者,我们经历过这类问题。如果事情太多,用8位数值已经不能表示,那么我们就试更宽的值,例如16位值。而且这很有趣的,正是Unicode被制定的原因。与混乱的256个字符代码映像,以及含有一些1字节代码和一些2字节代码的双字节字符集不同,Unicode是统一的16位系统,这样就允许表示65,536个字符。这对表示所有字符及世界上使用象形文字的语言,包括一系列的数学、符号和货币单位符号的集合来说是充裕的。
明白Unicode和DBCS之间的区别很重要。Unicode使用(特别在C程序设计语言环境里)「宽字符集」。「Unicode中的每个字符都是16位宽而不是8位宽。」在Unicode中,没有单单使用8位数值的意义存在。相比之下,在双字节字符集中我们仍然处理8位数值。有些字节自身定义字符,而某些字节则显示需要和另一个字节共同定义一个字符。
处理DBCS字符串非常杂乱,但是处理Unicode文字则像处理有秩序的文字。您也许会高兴地知道前128个Unicode字符(16位代码从0x0000到0x007F)就是ASCII字符,而接下来的128个Unicode字符(代码从0x0080到0x00FF)是ISO8859-1对ASCII的扩展。Unicode中不同部分的字符都同样基于现有的标准。这是为了便于转换。希腊字母表使用从0x0370到0x03FF的代码,斯拉夫语使用从0x0400到0x04FF的代码,美国使用从0x0530到0x058F的代码,希伯来语使用从0x0590到0x05FF的代码。中国、日本和韩国的象形文字(总称为CJK)占用了从0x3000到0x9FFF的代码。
Unicode的最大好处是这里只有一个字符集,没有一点含糊。Unicode实际上是个人计算机行业中几乎每个重要公司共同合作的结果,并且它与ISO10646-1标准中的代码是一一对应的。Unicode的重要参考文献是《The Unicode Standard,Version2.0》(Addison-Wesley出版社,1996年)。这是一本特别的书,它以其它文件少有的方式显示了世界上书写语言的丰富性和多样性。此外,该书还提供了开发Unicode的基本原理和细节。
Unicode有缺点吗?当然有。Unicode字符串占用的内存是ASCII字符串的两倍。(然而压缩文件有助于极大地减少文件所占的磁盘空间。)但也许最糟的缺点是:人们相对来说还不习惯使用Unicode。身为程序写作者,这就是我们的工作。
宽字符和 C
对C程序写作者来说,16位字符的想法的确让人扫兴。一个char和一个字节同宽是最不能确定的事情之一。没几个程序写作者清楚ANSI/ISO9899-1990,这是「美国国家标准程序设计语言-C」(也称作「ANSIC」)通过一个称作「宽字符」的概念来支持用多个字节代表一字符的字符集。这些宽字符与常用的字符完美地共存。
ANSIC也支持多字节字符集,例如中文、日文和韩文版本Windows支持的字符集。然而,这些多字节字符集被当成单字节构成的字符串看待,只不过其中一些字符改变了后续字符的含义而已。多字节字符集主要影响C语言程序执行时期链接库函数。相比之下,宽字符比正常字符宽,而且会引起一些编译问题。
宽字符不需要是Unicode。Unicode是一种可能的宽字符集。然而,因为本书的焦点是Windows而不是C执行的理论,所以我将把宽字符和Unicode作为同义语。
Char数据型态
假定我们都非常熟悉在C程序中使用char数据型态来定义和储存字符跟字符串。但为了便于理解C如何处理宽字符,让我们先回顾一下可能在Win32程序中出现的标准字符定义。
下面的语句定义并初始化了一个只包含一个字符的变量:
char c = 'A' ;
变量c需要1个字节来保存,并将用十六进制数0x41初始化,这是字母A的ASCII代码。
您可以像这样定义一个指向字符串的指针:
char * p ;
因为Windows是一个32位操作系统,所以指针变量p需要用4个字节保存。您还可初始化一个指向字符串的指针:
char * p = "Hello!" ;
像前面一样,变量p也需要用4个字节保存。该字符串保存在静态内存中并占用7个字节-6个字节保存字符串,另1个字节保存终止符号0。
您还可以像这样定义字符数组:
char a[10] ;
在这种情况下,编译器为该数组保留了10个字节的储存空间。表达式sizeof(a)将返回10。如果数组是整体变量(即在所有函数外定义),您可使用像下面的语句来初始化一个字符数组:
char a[] = "Hello!" ;
如果您将该数组定义为一个函数的区域变量,则必须将它定义为一个static变量,如下:
static char a[] = "Hello!" ;
无论哪种情况,字符串都储存在静态程序内存中,并在末尾添加0,这样就需要7个字节的储存空间。
宽字符
Unicode或者宽字符都没有改变char数据型态在C中的含义。char继续表示1个字节的储存空间,sizeof(char)继续返回1。理论上,C中1个字节可比8位长,但对我们大多数人来说,1个字节(也就是1个char)是8位宽。
C中的宽字符基于wchar_t数据型态,它在几个表头文件包括WCHAR.H中都有定义,像这样:
typedef unsigned short wchar_t ;
因此,wchar_t数据型态与无符号短整数型态相同,都是16位宽。
要定义包含一个宽字符的变量,可使用下面的语句:
wchar_t c = 'A' ;
变量c是一个双字节值0x0041,是Unicode表示的字母A。(然而,因为Intel微处理器从最小的字节开始储存多字节数值,该字节实际上是以0x41、0x00的顺序保存在内存中。如果检查Unicode文字的计算机储存应注意这一点。)
您还可定义指向宽字符串的指针:
wchar_t * p = L"Hello!" ;
注意紧接在第一个引号前面的大写字母L(代表「long」)。这将告诉编译器该字符串按宽字符保存-即每个字符占用2个字节。通常,指针变量p要占用4个字节,而字符串变量需要14个字节-每个字符需要2个字节,末尾的0还需要2个字节。
同样,您还可以用下面的语句定义宽字符数组:
static wchar_t a[] = L"Hello!" ;
该字符串也需要14个字节的储存空间,sizeof (a) 将返回14。索引数组a可得到单独的字符。a[1]的值是宽字符「e」,或者0x0065。
虽然看上去更像一个印刷符号,但第一个引号前面的L非常重要,并且在两个符号之间必须没有空格。只有带有L,编译器才知道您需要将字符串存为每个字符2字节。稍后,当我们看到使用宽字符串而不是变量定义时,您还会遇到第一个引号前面的L。幸运的是,如果忘记了包含L,C编译器通常会给提出警告或错误信息。
您还可在单个字符文字前面使用L前缀,来表示它们应解释为宽字符。如下所示:
wchar_t c = L'A' ;
但通常这是不必要的,C编译器会对该字符进行扩充,使它成为宽字符。