F1-Measure
F-Measure又称为F-Score,是IR(信息检索)领域的常用的一个评价标准,计算公式为:其中是参数,P是准确率(Precision),R是召回率(Recall)。[1]
F1-Measure
当参数=1时,就是最常见的F1-Measure了:F1 = 2P*R / (P+R)准确率与召回率
召回率和准确率是搜索引擎(或其它检索系统)的设计中很重要的两个概念和指标。召回率:Recall,又称“查全率”;准确率:Precision,又称“精度”、“正确率”。(Recall:the ability to remember sth. that you have learned orsth. that has happened in the past.)[2]在一个大规模数据集合中检索文档时,对每个查询(Query)我们可以统计出四个值::| 相关 | 不相关 | 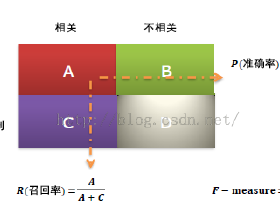 | ||
| 1 | 0 | 合计 | ||
| 检索到 | 1 | True Positive(TP) | False Positive(FP) | Predicted Positive(TP+FP) |
| 未检索到 | 0 | False Negative(FN) | True Negative(TN) | Predicted Negative(FN+TN) |
| 合计 | Actual Positive(TP+FN) | Actual Negative(FP+TN) | TP+FP+FN+TN |
“召回率”与“准确率”的关系
“召回率”与“准确率”虽然没有必然的关系(从上面公式中可以看到),然而在大规模数据集合中,这两个指标却是相互制约的。由于“检索策略”并不完美,希望更多相关的文档被检索到时,放宽“检索策略”时,往往也会伴随出现一些不相关的结果,从而使准确率受到影响。而希望去除检索结果中的不相关文档时,务必要将“检索策略”定的更加严格,这样也会使有一些相关的文档不再能被检索到,从而使召回率受到影响。凡是设计到大规模数据集合的检索和选取,都涉及到“召回率”和“准确率”这两个指标。而由于两个指标相互制约,我们通常也会根据需要为“检索策略”选择一个合适的度,不能太严格也不能太松,寻求在召回率和准确率中间的一个平衡点。这个平衡点由具体需求决定。 In this experimental workwe have proposed the new algorithm for oriented text detection fromthe acquired image, which is applied on 341 sample images. Theseimages were used to test the proposed algorithm and compared withexisting algorithms [16-17]. In all the three kinds of datasets, wehave computed the number of true text block detection (TDB), Numberof False Positives (NFP), number of Miss Detection Blocks (MDB) forthe number of actual text blocks (ATB) of an image.
3.1 Performance Measures for Text Frames
The performance of the proposed method is predicted as under bydefining the following quality measures:
Truly Detected Block (TDB): A detected block that contains a textstring, partially or fully.
Falsely Detected Block (FDB): A detected block that does notcontain text.
Text Block with Missing Data (MDB): A detected block that missessome characters of a text string (MDB is a subset of TDB).
For each image in the dataset, we manuallycount the number of Actual Text Blocks (ATB), i.e. the number oftrue text blocks in the frame.
Recall (R) = TDB/ ATB
Precision (P) = TDB / (TDB + FDB)
F-measure (F) = 2 × P × R / (P + R)
Misdetection Rate (MDR) = MDB / TDB
There are two otherperformance measures commonly used in the literature, DetectionRate and False Positive Rate; however, they can also be convertedto Recall and Precision:
Recall =Detection Rate and Precision = 1–False Positive Rate[18].
Hence only the above four performance measures are used forevaluation. Table-1 and Figure-2 gives the objective subjectiveanalysis of tested sample images for the performance of the twoexisting methods and the proposed method on the non-horizontal textdataset. The proposed method has the highest recall, the secondhighest precision (almost the same as that of Laplacian method) andthe highest F-measure.
This shows the advantage ofthe proposed method because it achieves good results while makingfewer assumptions about text and MDR, which is good as those of theSkeleton-Based method. The proposed methodachieves a relatively high detection rate (88.43%) on thenon-horizontal text dataset, which is much more challenging thangraphics text due to its arbitrary orientation and low contrast.However, the proposed method also has a high FPR.
[16] Trung Quy Phan, Palaiahnakote Shivakumara, Chew LimTan. DAS '10 Proceedings of the 9th IAPRInternational Workshopon Document Analysis Systems, 271-278.
[17] Shivakumara P.,Trung QuyPhan Chew Lim Tan.(2011)Pattern Analysisand Machine Intelligence, 412-419.
[18] Wong E.K.and Chen M.(2003) PatternRecognition, 1397-1406.