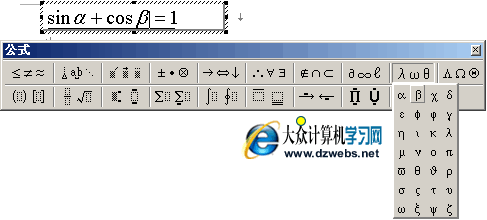
个性化推荐中的算法与推荐策略-路走的多了才成为路
在一个推荐场景上线之前,我们要做以下分析并调整推荐策略:
(1)分析该场景要推荐的网站对象(商品,买家,卖家,类目或者资讯):
a)已经有哪些用户行为:点击浏览、收藏、交易等,这影响到构建一个什么样的行为矩阵;
b)以上用户行为的数据量情况:如果行为量足够,可以考虑仅适用某种行为(比如,基于收藏行为,计算商品之间的行为相关性);如果数量不够,就需要综合足够多的行为数据,构建一个综合性的用户对象数据矩阵;
c)网站对象数量级:是百万,千万还是亿级别,这就需要考虑使用不同算法计算网站对象的相关性时,是否能够实现——比如,要约束具体每一个算法在2个小时内执行完;该问题需要和第二步综合起来考量。实在不行,可以将网站对象依据某些分类规则拆分成几个计算单元。
(2)这些网站对象是否在别的应用场景已经做了个性化推荐:
a)是否已经在“集体智慧”算法的推动下被展示给用户;
b)是否在别的逻辑下被“推荐”:比如,基于当前资讯所在类目,按点击量推荐或者按照文章发布日期推荐最新的。
对于一个全新的刚刚建立的网站,策略可以比较简单。比如推荐资讯文章,一般指只需要组合使用content-based算法(计算资讯的文本相关性)和item-based算法(计算资讯的行为相关性),可以考虑串行策略:优先使用item-based算法结果,如果数量不足,再使用content-based算法结果。
对于一个已经上线很久的网站,如果被推荐对象已经被“推荐”,比如基于类目按照发布日期被推荐。如果这个时候,还是单纯的串行组合使用item-based算法和content-based算法,效果很可能不怎么理想。因为,大量的相关用户行为,是在一个并不是很好的引导下形成的。这个时候,item-based算法出来的结果,和基于类目按照发布日期推荐的结果,在很大程度上存在重合。
这就是所谓的“路走多了才会成为路”,如果是一条弯路,则必须另辟蹊径,引导出一条新路——真正基于用户“集体智慧”的结果。
(1)刚开始的时候完全基于content-based算法结果进行推荐
Content-based算法结果是比上不足比下有余的,使用一段时间(具体看网站行为量,比如4周)后,再引入item-based算法;
(2)通过两个指标,在一定程度上减少“打酱油”行为的影响
l阈值min_support:表示该商品被点击查看过的人数
l阀值min_common_visit:以二项式为例,表示两个商品被同一个人看过,总的人数
通过这两个阀值,进行剪枝处理,裁剪掉大量的数据,减少了分布式计算量。
(3)item-based算法结果的阀值过滤先松后紧:先保证召回率,然后逐步提升准确率
例如,在网站真实推荐场景中,两周前对itembased算法的推荐阈值做了调整,之前因为担心推荐数量不够,设的阈值min_support和min_common_visit都为1(等于不设阈值),7月9日将这两个值修改为5和2。前后的效果的对比数据见下表:
统计日期 | 推荐场景 | 推荐算法 | 点击数 | 懒加载曝光PV | 曝光数 | 二跳率 | CTR |
6.12-6.15 | 83/**页面 | Itembased**算法 | 33,268 | 278,058 | 1,214,097 | 11.96% | 2.74% |
6.18-6.21 | 83/**页面 | Itembased**算法 | 38,763 | 323,305 | 1,395,984 | 11.99% | 2.78% |
6.25-6.29 | 83/**页面 | Itembased**算法 | 48,135 | 389,944 | 1,720,904 | 12.32% | 2.79% |
7.2-7.6 | 83/**页面 | Itembased**算法 | 44,201 | 360,531 | 1,567,397 | 12.27% | 2.82% |
7.9-7.13 | 83/**页面 | Itembased**算法 | 50,334 | 390,650 | 1,665,448 | 12.92% | 3.02% |
7.16-7.20 | 83/**页面 | Itembased**算法 | 50,546 | 395,322 | 1,700,736 | 12.81% | 2.97% |
在网站二跳率(点击/页面总数)和CTR(点击数/被曝光对象数)上还是有显著提升的(点击数等三项指标和全站流量有关)。