DedeCMS基于PHP+MySQL的技术开发,支持多种服务器平台,从2004年开始发布第一个版本开始,至今已经发布了五个大版本。DedeCMS以简单、健壮、灵活、开源几大特点占领了国内CMS的大部份市场,目前已经有超过35万个站点正在使用DedeCMS或基于DedeCMS核心开发,产品安装量达到95万。今天小编就带大家来体验一下DedeCMSv5.7的自带采集。
同样,织梦CMS内置了普通文章、图片集、软件等内容模型,我们来测试常用了文章和图片两个模型。为了能更好地与其他CMS做比较,我们的采集目标网站同上一期CMS自带采集体验系列之PHPCMSV9一样。
1、织梦CMS文章采集
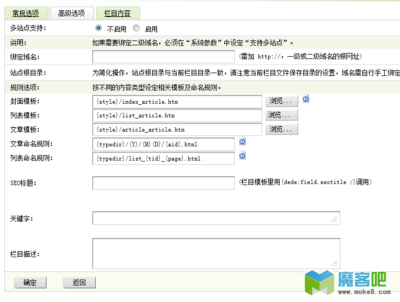
新建一个文章采集节点,后台——采集——采集节点管理——增加新节点,选择内容模型为普通文章。
设置节点基本信息。目标源码同上篇文章所说,通过查看目标网站源代码后设置,区域匹配模式默认字符串,只有在字符串无法确定区域的时候才用正则表达式,不过一般都用不上。最后就是织梦cms采集的特点之一防盗链模式,如果目标网站有防盗链功能则开启次功能可以成功采集,但是会降低采集速度。次测试目标网站没防盗链功能,所以不开启。
列表网站获取规则。同上篇文章分析,列表网址是有规律的可批量生成。这里要说下dedecms的强大之处,不仅获取列表网址的方式能灵活组合,而且如果目标网站整站使用的都是同一个模板,就可以启用“多栏目通配(#)”功能,通过设置后一个采集规则就可以采集整站并发布不同栏目了,而不需要一个栏目对应一个规则。(此功能小编会另外单独写一篇教程)
文章网址匹配规则。查看目标列表页源代码,设置要采集文章网址区域的开始和结束的html,接下来又是dedecms特点之一,如果采集网址页面链接有图片可直接设置采集为缩略图,非常方便。对区域网址进行再次筛选功能也有特色,除支持正则表达式外还声明了“必须包含”和“不能包含”的优先级,本篇体验目标站无干扰网址,所以留空。
保存并测试,系统会应用前面的设置测试采集网址,完整无误后保存信息并进入下一步内容采集设置。
网页内容获取规则。系统会默认一个采集url为预览网址,另外内容分页导航所在的区域匹配规则也很灵活,除了和phpcms一样有全“部列出的分页列表模式”、“上下页形式或不完整的分页列表模式”外,还多了一个“分页列表规则”。
各字段内容采集,dedecms的内容匹配规则和phpcms一样:“起始无重复HTML[内容]结尾无重复HTML”,[内容]即为所采内容。过滤规则是{dede:trimreplace=""}规则{/dede:trim},多个规则的话一个一行,如果要替换成指定的值,则只要在replace=""的引号里设置即可。
其中,内容摘要、关键字、缩略图系统会用正则进行自动匹配,我们只需设置过滤内容即可。其余字段分别设置匹配规则和过滤规则,系统同样自带了几个常用的过滤规则,但是点击“常用规则”后为弹出小窗口模式,稍微有点不方便。针对本测试的标题采集,以下两种方式都是可以的,如图:
文章作者、文章来源和发布时间字段一样采集,但是此版本dedecms在这几个字段下没有“自定义处理接口”了,如果有的话会稍显灵活,例如设置固定值可直接用“@me="固定值"”实现。现在不能用自定义处理接口设定固定值,也没有字段值设置,只能通过采集网页某一固定值然后用替换。如图:
dedecms的文章内容采集非常强大,除了匹配规则和过滤规则,还有个“自定义处理接口”。如果你有php基础的话,可以通过此功能对采集结果@me进行各种处理,强大到不行啊。以后小编会专门发一篇此功能的讲解文章。最后,不能直接在采集管理处新增采集字段,只能在对应内容模型管理中增加字段,采集管理会自动增加。如小编在“普通文章”内容模型那增加了一个“chinaz字段”,则采集设置中自动增了一个“chinaz字段”项目。
保存并测试,查看列表测试信息和网页规则测试,检查是否正确,无误后确定并开始采集。进入采集指定节点设置页面,因为小编之前有测试一遍,所以有60个历史种子网址,即小编之前已经采集了60个网址,另外还有几个选项大家按需求选择。
点开始采集网页,出现此采集提示信息显示采集进度,不知道是小编人品不好还是dede采集本身缺点,经常会浏览器没反应,采集停止在那,只有手动点击了才会继续。
采集完成后点右上角的“导出数据”,然后选择导出栏目,如果你在前面启用了“多栏目通配(#)”并指定了栏目ID,则要勾选此处的“批量采集选项”,其余选项根据自己需求选择,然后确定。如果勾选了“完成后自动生成导入内容HTML”则会在导入完后自动更新网站,否则就要先手动去生成。
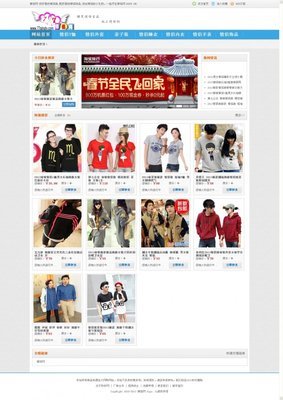
文章采集完成,看看效果:
列表页
内容页
下面来看看图片采集
2、织梦CMS图片采集
新建采集节点的时候选择“图片集”,进入到采集节点设置和文章采集一样,体验测试采集目标和上一篇文章一样为http://www.4493.com/mingxingxiezhen,设置如图:
设置完成后保存并测试,在测试界面我们就能直接看到缩略图了。
保存并进入网页内容获取规则,次目标站内容页是有分页的,源代码如下
所以我们选择“全部列出的分页列表”模式,并设置分页代码的唯一的开始和结束html代码:
接下来依次是关键词和描述过滤、标题获取、作者获取、来源获取和发布时间,最后来看看内容获取。图片采集内容部分两块,一个是图片集合一个是图集内容。图片集合就是图片了,其中系统默认填写了TurnTmageTag这个函数把采集到的图片处理为图集,图集内容就是你想要在页面显示的文章内容,比如对图片的描述等等,小编就直接采集标题作为图集内容:
保存并测试,查看测试结果。我们会发现dedecms的采集程序自动过滤img标签里面的其他代码,只取一个图片地址。这样有利也有弊,好处就是省了其他过滤规则,不好的地方就是图片alt表情直接默认为图1、图2……不利于网站优化。
查看结果无误后保存并采集,采集结束点导出数据发布,选择栏目后确定
发布完成,看看效果:
栏目页
内容页
总结:
强大,这是小编对织梦CMS自带采集程序的第一印象。从网址采集到缩略图处理,再到内容采集的自定义处理接口都让dedecms采集模块不会显得很死板,能灵活运用的话确实堪比火车头等专门的采集软件了。当然,想要将自定义处理接口充分使用起来的话,还是要有PHP语言基础的。最后小编在体验了PHPCMS和DEDECMS的采集之后有个很大的不解,各大CMS在做好程序功能的同时为什么就不能在一些细节的地方做好用户体验呢?!比如网址采集的匹配符“(*)”和文章内容采集的通配符“[内容]”都要用户手动输入,在旁边加上一个标签,直接用鼠标点击就在文本框中插入不是很方便么!(其他专业采集软件就是这么设置的)虽然只是一些细节,但也希望各大CMS能在功能强大的同时照顾用户使用体验。