
关�I词:新词发现;多字词;N-Gram;互信息;邻接熵
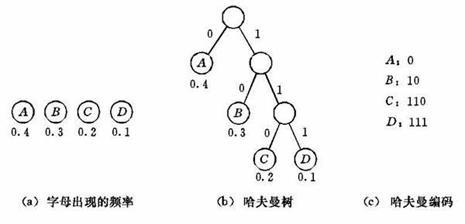
原文地址:熵编码——哈夫曼编码(转载)作者:吴双转载:用于学习参考,望原文作者海涵!数据压缩技术的理论基础是信息论。根据信息论的原理,可以找到最佳数据压缩编码方法,数据压缩的理论极限是信息熵。如果要求在编码过程中不丢失信息量,即要求
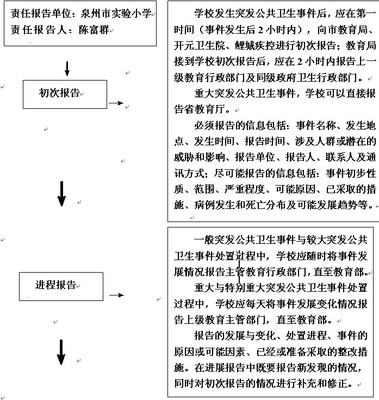
实验小学传染病疫情发现、信息登记及报告制度1、学校建立学生晨检、因病缺勤病因追查与登记制度。学校老师发现学生有传染病早期症状、疑似传染病病人以及因病缺勤等情况时,应及时报告给学校疫情报告人。学校疫情报告人应及时进行排
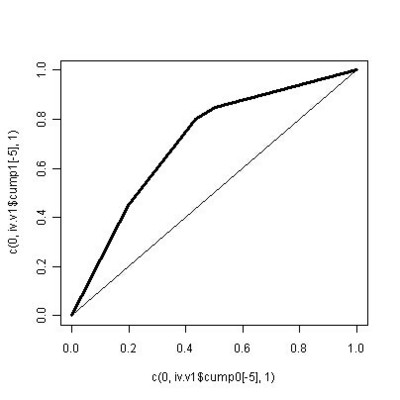
信用评分卡模型在国外是一种成熟的预测方法,尤其在信用风险评估以及金融风险控制领域更是得到了比较广泛的使用,其原理是将模型变量WOE编码方式离散化之后运用logistic回归模型进行的一种二分类变量的广义线性模型。 本文重点介绍模
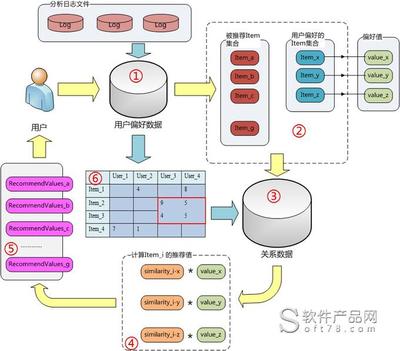
在上一篇博文中,我已经总结了几种主要的推荐方法,其中,基于内容和基于协同过滤是目前的主流算法,很多电子商务网站的推荐系统都是基于这两种算法的。基于内容在第一篇博文中已经详细介绍了,因此本博文主要是介绍基于协同过滤的个性化推荐
当我们需要对一个随机事件的概率分布进行预测时,我们的预测应当满足全部已知的条件,而对未知的情况不要做任何主观假设。在这种情况下,概率分布最均匀,预测的风险最小。因为这时概率分布的信息熵最大,所以称之为“最大熵法”。最大熵法在