SPSS应用软件试验指导手册
SPSS中文版工具
统计要与大量的数据打交道,涉及繁杂的计算和图表绘制。现代的数据分析工作如果离开统计软件几乎是无法正常开展。在准确理解和掌握了各种统计方法原理之后,再来掌握几种统计分析软件的实际操作,是十分必要的。
常见的统计软件有SAS,SPSS,MINITAB,EXCEL等。这些统计软件的功能和作用大同小异,各自有所侧重。其中的SAS和SPSS是目前在大型企业、各类院校以及科研机构中较为流行的两种统计软件。特别是SPSS,其界面友好、功能强大、易学、易用,包含了几乎全部尖端的统计分析方法,具备完善的数据定义、操作管理和开放的数据接口以及灵活而美观的统计图表制作。SPSS在各类院校以及科研机构中更为流行。
SPSS(Statistical Product and Service Solutions,意为统计产品与服务解决方案)。自20世纪60年代SPSS诞生以来,为适应各种操作系统平台的要求经历了多次版本更新,各种版本的SPSS for Windows大同小异,在本试验课程中我们选择PASW Statistics 18.0作为统计分析应用试验活动的工具。
1. SPSS的运行模式
SPSS主要有三种运行模式:
(1) 批处理模式
这种模式把已编写好的程序(语句程序)存为一个文件,提交给[开始]菜单上
[SPSS for Windows]→[Production Mode Facility]程序运行。
(2) 完全窗口菜单运行模式
这种模式通过选择窗口菜单和对话框完成各种操作。用户无须学会编程,简单易用。
(3) 程序运行模式
这种模式是在语句(Syntax)窗口中直接运行编写好的程序或者在脚本(script)窗口中运行脚本程序的一种运行方式。这种模式要求掌握SPSS的语句或脚本语言。
本试验指导手册为初学者提供入门试验教程,采用“完全窗口菜单运行模式”。
2. SPSS的启动
(1) 在windows[开始]→[程序]→[PASW],在它的次级菜单中单击“SPSS 12.0 for
Windows”即可启动SPSS软件,进入SPSS for Windows对话框,如图1.1,
图1.2所示。
1
SPSS应用软件试验指导手册
图1.1 SPSS启动
图1.1 PASW Statistics 启动对话框
3. SPSS软件的退出
SPSS软件的退出方法与其他Windows应用程序相同,有两种常用的退出方法: ? 按File→Exist的顺序使用菜单命令退出程序。
? 直接单击SPSS窗口右上角的“关闭”按钮,回答系统提出的是否存盘的问题之
后即可安全退出程序。
4. SPSS的主要窗口介绍
2
SPSS应用软件试验指导手册
SPSS软件运行过程中会出现多个界面,各个界面用处不同。其中,最主要的界面有三个:数据编辑窗口、结果输出窗口和语句窗口。
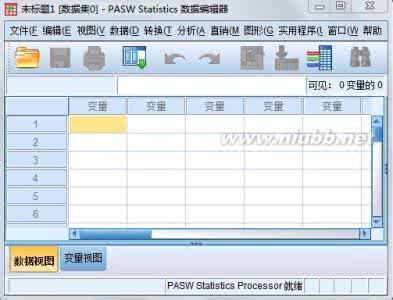
(1) 数据编辑窗口
启动SPSS后看到的第一个窗口便是数据编辑窗口,如图1.3所示。在数据编辑窗口中可以进行数据的录入、编辑以及变量属性的定义和编辑,是SPSS的基本界面。主要由以下几部分构成:标题栏、菜单栏、工具栏、编辑栏、变量名栏、观测序号、窗口切换标签、状态栏。
图1.3 数据浏览界面
? 标题栏:显示数据编辑的数据文件名。
? 菜单栏:通过对这些菜单的选择,用户可以进行几乎所有的SPSS操作。关于菜单的详细的操作步骤将在后续实验内容中分别介绍。
为了方便用户操作,SPSS软件把菜单项中常用的命令放到了工具栏里。当鼠标停留在某个工具栏按钮上时,会自动跳出一个文本框,提示当前按钮的功能。另外,如果用户对系统预设的工具栏设置不满意,也可以用[视图]→[工具栏] →[设定]命令对工具栏按钮进行定义。
? 编辑栏:可以输入数据,以使它显示在内容区指定的方格里。
? 变量名栏:列出了数据文件中所包含变量的变量名
3
SPSS应用软件试验指导手册
? 观测序号:列出了数据文件中的所有观测值。观测的个数通常与样本容量的大小一致。
? 窗口切换标签:用于“数据视图”和“变量视图”的切换。即数据浏览窗口与变量浏览窗口。数据浏览窗口用于样本数据的查看、录入和修改。变量浏览窗口用于变量属性定义的输入和修改。
? 状态栏:用于说明显示SPSS当前的运行状态。SPSS被打开时,将会显示“PASW Statistics Processor”的提示信息。
(2) 结果输出窗口
在SPSS中大多数统计分析结果都将以表和图的形式在结果观察窗口中显示。窗口右边部分显示统计分析结果,左边是导航窗口,用来显示输出结果的目录,可以通过单击目录来展开右边窗口中的统计分析结果。当用户对数据进行某项统计分析,结果输出窗口将被自动调出。当然,用户也可以通过双击后缀名为.spo的SPSS输出结果文件来打开该窗口。
4
SPSS应用软件试验指导手册
试验1 数据文件管理
一、试验目的与要求
通过本试验项目,使学生理解并掌握SPSS软件包有关数据文件创建和整理的基本操作,学习如何将收集到的数据输入计算机,建成一个正确的SPSS数据文件,并掌握如何对原始数据文件进行整理,包括数据查询,数据修改、删除,数据的排序等等。
二、试验原理
SPSS数据文件是一种结构性数据文件,由数据的结构和数据的内容两部分构成,也可以说由变量和观测两部分构成。一个典型的SPSS数据文件如表2.1 所示。
表2.1 SPSS数据文件结构
SPSS变量的属性
SPSS中的变量共有10个属性,分别是变量名(Name)、变量类型(Type)、长度(Width)、小数点位置(Decimals)、变量名标签(Label)、变量名值标签(Value)、缺失值(Missing)、数据列的显示宽度(Columns)、对其方式(Align)和度量尺度(Measure)。定义一个变量至少要定义它的两个属性,即变量名和变量类型,其他属性可以暂时采用系统默认值,待以后分析过程中如果有需要再对其进行设置。在spss数据编辑窗口中单击“变量视窗”标签,进入变量视窗界面(如图2.1所示)即可对变量的各个属性进行设置。
5
SPSS应用软件试验指导手册
图2.1 变量视窗
三、试验内容与步骤
1.创建一个数据文件
数据文件的创建分成三个步骤:
(1)选择菜单 【文件】→【新建】→【数据】新建一个数据文件,进入数据编辑窗口。窗口顶部标题为“PASW Statistics数据编辑器”。
(2)单击左下角【变量视窗】标签进入变量视图界面,根据试验的设计定义每个变量类型。
(3)变量定义完成以后,单击【数据视窗】标签进入数据视窗界面,将每个具体的变量值录入数据库单元格内。
2.读取外部数据
当前版本的SPSS可以很容易地读取Excel数据,步骤如下:
(1)按【文件】→【打开】→【数据】的顺序使用菜单命令调出打开数据对话框,在文件类型下拉列表中选择数据文件,如图2.2所示。
6
SPSS应用软件试验指导手册
图2.2 Open File对话框
(2)选择要打开的Excel文件,单击“打开”按钮,调出打开Excel数据源对话框,如图2.3所示。对话框中各选项的意义如下:
工作表 下拉列表:选择被读取数据所在的Excel工作表。
范围 输入框:用于限制被读取数据在Excel工作表中的位置。
图2.3 Open Excel Data Source对话框
3.数据编辑
7
SPSS应用软件试验指导手册
在SPSS中,对数据进行基本编辑操作的功能集中在Edit和Data菜单中。
4.SPSS数据的保存
SPSS数据录入并编辑整理完成以后应及时保存,以防数据丢失。保存数据文件可以通过【文件】→【保存】或者【文件】→【另存为】菜单方式来执行。在数据保存对话框(如图2.5所示)中根据不同要求进行SPSS数据保存。
图2.5 SPSS数据的保存
5. 数据整理
在SPSS中,数据整理的功能主要集中在【数据】和【转换】两个主菜单下。
(1)数据排序(Sort Case)
对数据按照某一个或多个变量的大小排序将有利于对数据的总体浏览,基本操作说明如下:
? 选择菜单【数据】→【排列个案】,打开对话框,如图2.7所示。
(2)抽样(Select Case)
在统计分析中,有时不需要对所有的观测进行分析,而可能只对某些特定的对象有兴趣。利用SPSS的Select Case命令可以实现这种样本筛选的功能。以SPSS安装配套数据文件Growth study.sav为例,选择年龄大于10的观测,基本操作说明 8
SPSS应用软件试验指导手册
图2.7 排列个案 对话框
如下:
? 打开数据文件Growth study.sav,选择【数据】→【选择个案】命令,打开
对话框,如图2.8
图2.8 选择个案对话框
? 指定抽样的方式:【全部个案】不进行筛选;【如果条件满足】按指定条件进
行筛选。本例设置:产品数量>150,如图2.9所示;
9
SPSS应用软件试验指导手册
图2.9 选择个案 对话框
设置完成以后,点击continue,进入下一步。
? 确定未被选择的观测的处理方法,这里选择默认选项【过滤掉未选定的个案】。
? 单击ok进行筛选,结果如图
2.10
图2.10 选择个案的结果
(3)增加个案的数据合并(【合并文件】→【添加个案】)
将新数据文件中的观测合并到原数据文件中,在SPSS中实现数据文件纵向合并的方法如下:
10
SPSS应用软件试验指导手册
选择菜单【数据】→【合并文件】→【添加个案】,如图2.11,选择需要追加的数据文件,单击打开按钮,弹出Add Cases对话框,如图2.12。
图2.11 选择个体数据来源的文件
图2.12 选择变量
(4)增加变量的数据合并(【合并文件】→【添加变量】)
增加变量时指把两个或多个数据文件实现横向对接。例如将不同课程的成绩文 11
SPSS应用软件试验指导手册
件进行合并,收集来的数据被放置在一个新的数据文件中。在SPSS中实现数据文件横向合并的方法如下:
选择菜单【数据】→【合并文件】→【添加变量】,选择合并的数据文件,单击“打开”,弹出添加变量,如图2.12所示。
图2.12
? 单击Ok执行合并命令。这样,两个数据文件将按观测的顺序一对一地横向
合并。
(5)数据拆分(Split File)
在进行统计分析时,经常要对文件中的观测进行分组,然后按组分别进行分析。例如要求按性别不同分组。在SPSS中具体操作如下:
? 选择菜单【数据】→【分割文件】,打开对话框,如图2.13所示。
12
SPSS应用软件试验指导手册
图2.13 分割文件对话框
? 选择拆分数据后,输出结果的排列方式,该对话框提供了3种方式:对全部
观测进行分析,不进行拆分;在输出结果种将各组的分析结果放在一起进行
比较;按组排列输出结果,即单独显示每一分组的分析结果。
? 选择分组变量
? 选择数据的排序方式
? 单击ok按钮,执行操作
(6)计算新变量
在对数据文件中的数据进行统计分析的过程中,为了更有效地处理数据和反映事务的本质,有时需要对数据文件中的变量加工产生新的变量。比如经常需要把几个变量加总或取加权平均数,SPSS中通过【计算】菜单命令来产生这样的新变量,其步骤如下:
? 选择菜单【转换】→【计算变量】,打开对话框,如图2.14所示。
13
SPSS应用软件试验指导手册
图2.14 Compute Variable对话框
? 在目标变量输入框中输入生成的新变量的变量名。单击输入框下面类型与标签按钮,在跳出的对话框中可以对新变量的类型和标签进行设置。
? 在数字表达式输入框中输入新变量的计算表达式。例如“年龄>20”。
? 单击【如果】按钮,弹出子对话框,如图2.15所示。包含所有个体:对所有的观测进行计算;如果个案满足条件则包括:仅对满足条件的观测进行计算。 ? 单击Ok按钮,执行命令,则可以在数据文件中看到一个新生成的变量。
14
SPSS应用软件试验指导手册
图2.15如果?子对话框
四、备择试验
某航空公司38名职员性别和工资情况的调查数据,如表2.3所示,试在SPSS中进行如下操作:
(1)将数据输入到SPSS的数据编辑窗口中,将gender定义为字符型变量,将salary定义为数值型变量,并保存数据文件,命名为“试验1-1.sav”。
(2)插入一个变量income,定义为数值型变量。
(3)将数据文件按性别分组
(4)查找工资大于40000美元的职工
(5)当工资大于40000美元时,职工的奖金是工资的20%;当工资小于40000美元时,职工的奖金是工资的10%,假设实际收入=工资+奖金,计算所有职工的实际收入,并添加到income变量中。
15
SPSS应用软件试验指导手册
16
SPSS应用软件试验指导手册
试验2 描述统计
一、试验目的与要求
统计分析的目的在于研究总体特征。但是,由于各种各样的原因,我们能够得到的往往只能是从总体中随机抽取的一部分观察对象,他们构成了样本,只有通过对样本的研究,我们才能对总体的实际情况作出可能的推断。因此描述性统计分析是统计分析的第一步,做好这一步是进行正确统计推断的先决条件。通过描述性统计分析可以大致了解数据的分布类型和特点、数据分布的集中趋势和离散程度,或对数据进行初步的探索性分析(包括检查数据是否有错误,对数据分布特征和规律进行初步观察)。
本本试验旨在于:引到学生利用正确的统计方法对数据进行适当的整理和显示,描述并探索出数据内在的数量规律性,掌握统计思想,培养学生学习统计学的兴趣,为继续学习推断统计方法及应用各种统计方法解决实际问题打下必要而坚实的基础。
二、试验原理
描述统计是统计分析的基础,它包括数据的收集、整理、显示,对数据中有用信息的提取和分析,通常用一些描述统计量来进行分析。
集中趋势的特征值:算术平均数、调和平均数、几何平均数、众数、中位数等。其中均数适用于正态分布和对称分布资料,中位数适用于所有分布类型的资料。
离散趋势的特征值:全距、内距、平均差、方差、标准差、标准误、离散系数等。其中标准差、方差适用于正态分布资料,标准误实际上反映了样本均数的波动程度。
分布特征值:偏态系数、峰度系数、他们反映了数据偏离正态分布的程度。
三、试验内容与步骤
下面给出的一个例题是来自SPSS软件自带的数据文件“Employee.data”,该文件包含某公司员工的工资、工龄、职业等变量,我们将利用此例题给出相关的描述统计说明,本例中,我们将以员工的当前工资为例,计算该公司员工当前工资的一些描述统计量,如均值、频数、方差等描述统计量的计算。
1.频数分析(Frequencies)1
基本统计分析往往从频数分析开始。通过频数分析能够了解变量取值的状况,1频数分析多适用于离散变量,其功能是描述离散变量的分布特征。
17
SPSS应用软件试验指导手册
对把握数据的分布特征是非常有用的。比如,在某项调查中,想要知道被调查者的性别分布状况。频数分析的第一个基本任务是编制频数分布表。SPSS中的频数分布表包括的内容有:
(1)频数(Frequency)即变量值落在某个区间中的次数。
(2)百分比(Percent)即各频数占总样本数的百分比。
(3)有效百分比(Valid Percent)即各频数占有效样本数的百分比。这里有效样本数=总样本-缺失样本数。
(4)累计百分比(Cumulative Percent)即各百分比逐级累加起来的结果。最终取值为百分之百。
频数分析的第二个基本任务是绘制统计图。统计图是一种最为直接的数据刻画方式,能够非常清晰直观地展示变量的取值状况。频数分析中常用的统计图包括:条形图,饼图,直方图等。
频数分析的应用步骤
在SPSS中的频数分析的实现步骤如下:
选择菜单“【文件】—>【打开】—>【数据】”在对话框中找到需要分析的数据文件“SPSS/Employee data”,然后选择“打开”。
选择菜单“【分析】—>【描述统计】—>【频率】”。如图2.1所示
询问是否输出频数分布表
图2.1 Frequencies对话框
确定所要分析的变量,例如 年龄
在变量选择确定之后,在同一窗口上,点击“Statistics”按钮,打开统计量对话框,如下图2.2所示,选择统计输出选项。
18
SPSS应用软件试验指导手册
图2.2 统计量子对话框
图2.3 Charts子对话框
结果输出与分析
点击Frequencies 对话框中的“OK”按钮,即得到下面的结果。 表2.4 描述性统计量
Statistics
19
SPSS应用软件试验指导手册
表2.4中给出了总样本量(N),其中变量Gender的有效个数(Valid)为474个、缺失值(missing)为0。
表2.5中,Frequency是频数,Percent是按总样本量为分母计算的百分比,Valid Percent是以有效样本量为分母计算的百分比,Cumulative Percent是累计百分比。
图2.5变量Gender的条形图,图2.6变量Gender的饼图。
图2.5 变量gender的条形图
图2.6 变量gender的饼图
2.描述统计(Descriptives)2
SPSS的【描述】命令专门用于计算各种描述统计性统计量。本节利用某年国内上市公司的财务数据来介绍描述统计量在SPSS中的计算方法。具体操作步骤如下:
选择菜单【分析】→【描述统计】→【描述】,如图2.7所示
2
描述统计主要对定距型或定比型数据的分布特征作具体分析。
20
SPSS应用软件试验指导手册
图2.7 描述 对话框
将待分析的变量移入Variables列表框,例如将每股收益率、净资产收益率、资产负债率等2个变量进行描述性统计,以观察上市公司股权集中度情况和负债比率的高低。
Save standardized values as variables,对所选择的每个变量进行标准化处理,产生相应的Z分值,作为新变量保存在数据窗口中。其变量名为相应变量名前加前缀z。标准化计算公式:
xi?s
单击【选项】按钮,如图2.8 所示,选择需要计算的描述统计量。各描述统计Zi?量同Frequencies命令中的Statistics子对话框中大部分相同,这里不再重复。
21
SPSS应用软件试验指导手册
图2.8 选项 子对话框
在主对话框中单击ok执行操作。 结果输出与分析
在结果输出窗口中给出了所选变量的相应描述统计,如表2.6所示。从表中可以看到,我国上市公司前两大股东持股比例之比平均高达102.9,说明“一股独大”的现象比较严重;前五大股东持股比例之和平均为51.8%,资产负债率平均为46.78%。
另外,从偏态和峰度指标看出,前两大股东持股比例之比的分布呈现比较明显的右偏,而且比较尖峭。为了验证这一结论,可以利用Frequencies命令画出变量z的直方图,如图2.9
表2.6 描述统计量表 Descriptive Statistics
22
SPSS应用软件试验指导手册
图2.9 变量Z的直方图
3.探索分析(Explore)
调用此过程可对变量进行更为深入详尽的描述性统计分析,故称之为探索分析。它在一般描述性统计指标的基础上,增加有关数据其他特征的文字与图形描述,显得更加细致与全面,对数据分析更进一步。
探索分析一般通过数据文件在分组与不分组的情况下获得常用统计量和图形。一般以图形方式输出,直观帮助研究者确定奇异值、影响点、还可以进行假设检验,以及确定研究者要使用的某种统计方式是否合适。
在打开的数据文件上,选择如下命令:选择菜单“【分析】—>【描述统计】—>【探索】”,打开对话框。
23
SPSS
应用软件试验指导手册
因变量列表;待分析的变量名称,例如将每股收益率作为研究变量。
因子列表:从源变量框中选择一个或多个变量进入因子列表,分组变量可以将数据按照该观察值进行分组分析。
标准个案:在源变量表中指定一个变量作为观察值的标识变量。
在输出栏中,选择两者都,表示输出图形及描述统计量。
选择【统计量】按钮,选择想要计算的描述统计量。如图所示
对所要计算的变量的频数分布及其统计量值作图 打开“Plots对话框”,出现如下图。
? 结果的输出与说明
24
SPSS应用软件试验指导手册
(1)Case Processing Summary 表
在Case Processing Summary 表中可以看出female 有216个个体,Male258个个体,均无缺失值。
(2)Descriptives 表
Current Salary
Gender Female
Mean
95% Confidence Lower Bound Interval for Mean Upper Bound 5% Trimmed Mean Median Variance Std. Deviation Minimum Maximum Range
Interquartile Range Skewness Kurtosis
Male
Mean
95% Confidence Lower Bound Interval for Mean Upper Bound 5% Trimmed Mean Median Variance Std. Deviation Minimum Maximum Range
Interquartile Range Skewness Kurtosis
Descriptives
Statistic $26,031.92 $25,018.29 $27,045.55 $25,248.30 $24,300.00 57123688.2
68
$7,558.021
$15,750 $58,125 $42,375 $7,013 1.863 4.641 $41,441.78 $39,051.19 $43,832.37 $39,445.87 $32,850.00 380219336.
303
$19,499.214
$19,650 $135,000 $115,350 $22,675 1.639 2.780
Std. Error $514.258
.166 .330 $1,213.96
8 .152 .302
(3)职位员工薪水直方图显示
25
SPSS应用软件试验指导手册
(4)茎叶图描述
茎叶图自左向右可以分为3 大部分:频数(Frequency)、茎(Stem)和叶(Leaf)。茎表示数值的整数部分,叶表示数值的小数部分。每行的茎和每个叶组成的数字相加再乘以茎宽(Stem Width),即茎叶所表示的实际数值的近似值。
Current Salary Stem-and-Leaf Plot for
gender= Female
Frequency Stem & Leaf
2.00 1 . 55
16.00 1 . 6666666666777777
14.00 1 . 88889999999999
31.00 2 . 0000000000000111111111111111111
35.00 2 . 22222222222222222222233333333333333
38.00 2 . 44444444444444444444444444555555555555
22.00 2 . 6666666666677777777777
17.00 2 . 88888899999999999
7.00 3 . 0001111
8.00 3 . 22233333
8.00 3 . 44444555
5.00 3 . 66777
2.00 3 . 88
26
SPSS应用软件试验指导手册
11.00 Extremes (>=40800)
Stem width: 10000 Each leaf: 1 case(s)
(5)箱图
图中灰色区域的方箱为箱图的主体,上中下3 条线分别表示变量值的第75、50、25百分位数,因此变量的50%观察值落在这一区域中。
方箱中的中心粗线为中位数。箱图中的触须线是中间的纵向直线,上端截至线为变量的最大值,下端截至线为变量的最小值。
四、备择试验
完成下列试验内容,并按试验(1)所附试验报告的格式撰写报告。
1.表2.7为某班级16位学生的身高数据,对其进行频数分析,并对实验报告作出说明。
27
SPSS应用软件试验指导手册
2.测量18台电脑笔记重量,见表2.8,对其进行描述统计量分析,并对试验结果作出说明。
28
SPSS应用软件试验指导手册
试验3:统计推断
一、试验目的与要求
1.熟悉点估计概念与操作方法
2.熟悉区间估计的概念与操作方法
3.熟练掌握T检验的SPSS操作
4.学会利用T检验方法解决身边的实际问题
二、试验原理
1.参数估计的基本原理
2.假设检验的基本原理
三、试验演示内容与步骤
1.单个总体均值的区间估计
例题:为研究在黄金时段中,即每晚8:30-9:00 内,电视广告所占时间的多少。美国广告协会抽样调查了20个最佳电视时段中广告所占的时间(单位:分钟)。请给出每晚8:30 开始的半小时内广告所占时间区间估计,给定的置信度为95%。 操作程序:
? 打开SPSS,建立数据文件:“ 电视节目市场调查.sav”。这里,研究变量为:time,即每天看电视的时间。
? 选择区间估计选项,方法如下: 选择菜单【分析】—>【描述统计】—>【探索】” ,打开图3.1Explore 对话框。
? 从源变量清单中将“time”变量移入Dependent List框中。
29
SPSS
应用软件试验指导手册
图3.1 Explore对话框
? 单击上图右方的“统计量”按钮打开“探索:统计量”对话框。在设置均值的置信水平,如键入95%,完成后单击“继续”按钮回到主窗口。
图3.2 探索 统计量设置窗口
? 返回主窗口点击ok运行操作。 ? 计算结果简单说明:
表3.1 描述统计量 Descriptives
time
Mean
95% Confidence
Lower Bound
Interval for Mean
Upper Bound 5% Trimmed Mean Median Variance Std. Deviation Minimum Maximum Range
Interquartile Range Skewness Kurtosis
Statistic 6.5350 6.2529 6.8171 6.5167 6.4500 .363 .60287 5.60 7.80 2.20 .95 .295 -.612
Std. Error
.13480
.512 .992
? 如上表显示。从上表“ 95% Confidence Interval for Mean ”中可以得出,每晚8:30 开始的半小时内广告所占时间区间估计(置信度为95%) 为:(6.2529,6.8171),其中lower Bound 表示置信区间的下限,Upper Bound表示置信区间的上限。点估计是:6.5350。
30
SPSS应用软件试验指导手册
2.两个总体均值之差的区间估计
例题:The Wall Street Journal(1994,7 )声称在制造业中,参加工会的妇女比未参加工会的妇女的报酬要多2.5 美元。想通过统计方法,对这个观点是否正确给出检验。
假设抽取了7位女性工会会员与8位非工会会员女性报酬数据。要求对制造业中参加工会会员的女性报酬与未参加工会的女性报酬平均工资之差进行区间估计,预设的置信度为95%。
? 打开SPSS,按如下图示格式输入原始数据,建立数据文件:“工会会员工资差别.spss”。这里,“会员”表示是否为工会会员的变量,y 表示是工会会员,n表示非工会会员,“报酬”表示女性员工报酬变量,单位:千美元。
? 计算两总体均值之差的区间估计,采用“独立样本T 检验”方法。选择菜单“ 【分析】→【比较均值】→独立样本T检验”, 打开对话框。
? 变量选择
(1)从源变量清单中将“报酬”变量移入检验变量框中。表示要求该变量的均值的区间估计。
(2)从源变量清单中将“group”变量移入分组变量框中。表示总体的分类变量。
图3.3 独立样本T检验 对话框
? 定义分组 单击定义组按钮,打开Define Groups 对话框。在Group1 中输入1,在Group2 中输入2(1表示非工会会员,2 表示工会会员)。完成后单击“继续” 31
SPSS应用软件试验指导手册
按钮回到主窗口。
图3.4 define groups设置窗口
? 计算结果 单击上图中“OK”按钮,输出结果如下图所示。
(1)Group Statistics(分组统计量)表
分别给出不同总体下的样本容量、均值、标准差和平均标准误。从该表中可以看出,参加工会的妇女平均报酬为19.925,不参加工会的妇女平均报酬为20.1429。
表3.2 分组统计量
Group Statistics
(2)Independent Sample Test (独立样本T 检验)表
Levene’s Test for Equality of Variance,为方差检验,在Equal variances assumed (原假设:方差相等)下,F=0.623, 因为其P-值大于显著性水平,即:Sig.=0.444>0.05, 说明不能拒绝方差相等的原假设,接受两个总体方差是相等的假设。因此参加工会会员的女性报酬与未参加工会的女性报酬平均工资之差95%的区间估计为[0.76842,0.33271]。
T-test for Equality of Means 为检验总体均值是否相等的t 检验,由于在本例中,其P-值大于显著性水平,即:Sig.=0.408>0.05, 因此不应该拒绝原假设,也就是说参加工会的妇女跟未参加工会的妇女的报酬没有显著差异。本次抽样推断结论不支持The Wall Street Journal(1994,7 )提出的“参加工会的妇女比未参加工会的妇女的报酬要多2.5 美元”观点,即参加工会的妇女不比未参加工会的妇女的报酬多。
32
SPSS应用软件试验指导手册
表3.3 独立样本T检验结果 Independent Samples Test
Levene's Test for Equality of Variances F
报酬
-.855 13 -.848 12.187
Sig.
t
df
t-test for Equality of Means
Std. Error Differenc
e
.25485 .25697
95% Confidence Interval of the Difference Lower -.76842 -.77679
Upper .33271 .34108
Sig. Mean (2-tailed) Difference
.408 .413
-.21786 -.21786
Equal variances .623 .444 assumed Equal variances not assumed
3.单个总体均值的假设检验 (单样本T检验)
例子:某种品牌的沐浴肥皂制造程序的设计规格中要求每批平均生产120 块肥皂,高于或低于该数量均被认为是不合理的,在由10 批产品所组成的一个样本中,每批肥皂的产量数据见下表,在0.05 的显著水平下,检验该样本结果能否说明制造过程运行良好?
? 判断检验类型 该例属于“大样本、总体标准差σ未知。假设形式为:
H0:μ=μ
0,
H1 :μ≠μ0
? 软件实现程序 打开已知数据文件,然后选择菜单“【分析】→【比较均值】→单样本T检验”,打开One-Sample T Test 对话框。从源变量清单中将“产品数量”向右移入“Test Variables”框中。
图3.5 one-sample T test窗口
33
SPSS应用软件试验指导手册
在“Test Value” 框里输入一个指定值(即假设检验值,本例中假设为120),T 检验过程将对每个检验变量分别检验它们的平均值与这个指定数值相等的假设。
? “One-Sample T Test”窗口中“OK”按钮,输出结果如下表所示。
(1)“One-Sample Statistics”(单个样本的统计量)表 分别给出样本的容量、均值、标准差和平均标准误。本例中,产品数量均值为118.9000。
表3.4 单样本统计量
One-Sample Statistics
(2)“One-Sample Test”(单个样本的检验)表 表中的t 表示所计算的T 检验统计量的数值,本例中为-0.705。 表中的“df”,表示自由度,本例中为9。 表中的“Sig”(双尾T 检验), 表示统计量的P-值, 并与双尾T检验的显著性的大小进行比较:Sig.=0.498>0.05,说明这批样本的平均产量与120 无显著差异。 表中的“Mean Difference”, 表示均值差,即样本均值与检验值120 之差, 本例中为-1.1000。表中的“95% Confidence Internal of the Difference”, 样本均值与检验值偏差的95%置信区间为(-4.628,2.428),置信区间包括数值0,说明样本数量与120 无显著差异,符合要求。
表3.5 单样本T检验结果 One-Sample Test
4.两独立样本的假设检验(两独立样本T检验)
例题:The Wall Street Journal(1994,7 )声称在制造业中,参加工会的妇女比未参加工会的妇女的报酬要多2.5 美元。想通过统计方法,对这个观点是否正确给出检验。
假设抽取了7位女性工会会员与8位非工会会员女性报酬数据。要求对制造业中参加工会会员的女性报酬与未参加工会的女性报酬平均工资之差进行区间估计,预设的置信度为95%。
? 打开SPSS,按如下图示格式输入原始数据,建立数据文件:“工会会员工资
34
SPSS应用软件试验指导手册
差别.sav”。这里,“会员”表示是否为工会会员的变量,y 表示是工会会员,n表示非工会会员,“报酬”表示女性员工报酬变量,单位:千美元。
? 计算两总体均值之差的区间估计,采用“独立样本T 检验”方法。选择菜单“ 【分析】→【比较均值】→【独立样本T检验】”。
(1)从源变量清单中将“报酬”变量移入检验变量框中。表示要求该变量的均值的检验。
(2)从源变量清单中将“会员”变量移入分组变量框中。表示总体的分类变量。
图3.6 sample T test 窗口
? 定义分组 单击Grouping Variable 框下面的Define Groups 按钮,打开Define Groups 对话框。在Group1 中输入1,在Group2 中输入2(1表示非工会会员,2 表示工会会员)。完成后单击“继续”按钮返回主窗口。
图3.7 define groups对话框
35
SPSS应用软件试验指导手册
? 计算结果 单击上图中“OK”按钮,输出结果如下图所示。 (1)Group Statistics(分组统计量)表
分别给出不同总体下的样本容量、均值、标准差和平均标准误。从该表中可以看出,参加工会的妇女平均报酬为19.925,不参加工会的妇女平均报酬为20.1429。
表3.6 分组统计量 Group Statistics
(2)Independent Sample Test (独立样本T 检验)表
Levene’s Test for Equality of Variance,为方差检验,在Equal variances assumed (原假设:方差相等)下,F=0.623, 因为其P-值大于显著性水平,即:Sig.=0.444>0.05, 说明不能拒绝方差相等的原假设,接受两个总体方差是相等的假设。
T-test for Equality of Means 为检验总体均值是否相等的t 检验,由于在本例中,其P-值大于显著性水平,即:Sig.=0.408>0.05, 因此不应该拒绝原假设,也就是说参加工会的妇女跟未参加工会的妇女的报酬没有显著差异。本次抽样推断结论不支持The Wall Street Journal(1994,7 )提出的“参加工会的妇女比未参加工会的妇女的报酬要多2.5 美元”观点,即参加工会的妇女不比未参加工会的妇女的报酬多。
表3.7 独立样本T检验结果 Independent Samples Test
5.配对样本T检验
36
SPSS应用软件试验指导手册
配对样本是对应独立样本而言的,配对样本是指一个样本在不同时间做了两次试验,或者具有两个类似的记录,从而比较其差异;独立样本检验是指不同样本平均数的比较,而配对样本检验往往是对相同样本二次平均数的检验。
配对样本T检验的前提条件为:第一,两样本必须是配对的。即两样本的观察值数目相同,两样本的观察值顺序不随意更改。第二,样本来自的两个总体必须服从正态分布。例如针对试验前学习成绩何智商相同的两组学生,分别进行不同教学方法的训练,进行一段时间试验教学后,比较参与试验的两组学生的学习成绩是否存在显著性差异。
假设某校为了检验进行新式培训前后学生的学习成绩是否有了显著提高,从全校学生中随机抽出30名进行测试,这些学生培训前后的考试成绩放置于数据文件“学生培训.sav”中。在SPSS中对这30名学生的成绩进行配对样本t检验的操作步骤如下:
? 选择菜单【分析】→【比较均值】→【配对样本T检验】,打开对话框,如图3.8所示,将两个配对变量移入右边的Pair Variables列表框中。移动的方法是先选择其中的一个配对变量,再选择第二个配对变量,接着单击中间的箭头按钮。
图3.8 Paired-Samples T Test对话框
? 选项按钮的用于设置置信度选项,这里保持系统默认的95%
? 在主对话框中单击ok按钮,执行操作。
? 实例结果分析
表3.8和表3.9给出了培训前后学生考试成绩的均值、标准差、均值标准误差以及培训前后成绩的相关系数。从表3.8来看,培训前后平均成绩并没有发生显著的提高。
37
SPSS应用软件试验指导手册
表3.10给出了配对样本t检验结果,包括配对变量差值的均值、标准差、均值标准误差以及差值的95%置信度下的区间估计。当然也给出了最为重要的t统计量和p值。结果显示p=0.246>0.05,所以,学校的所谓新式培训并未带来学生成绩的显著变化。
表3.8 培训前后成绩的描述统计量 Paired Samples Statistics
表3.9 培训前后成绩的相关系数 Paired Samples Correlations
表3.10 配对样本T检验结果
四、备择试验
1.某省大学生四级英语测验平均成绩为65,现从某高校随机抽取20份试卷,其分数为:72、76、68、78、62、59、64、85、70、75、61、74、87、83、54、76、56、66、68、62,问该校英语水平与全区是否基本一致?设α=0.05
2.分析某班级学生的高考数学成绩是否存在性别上的差异。数据如表所示:
某班级学生的高考数学成绩
性别
数学成绩 75 80
女(n=12) 92 96 86 83 78 87 70 65 70 65 70 78 72 56 3.SPSS自带的数据文件world95.sav中,保存了1995年世界上109个国家和地区的部分指标的数据,其中变量“lifeexpf”,“lifeexpm”分别为各国或地区女性和男性人口的平均寿命。假设将这两个指标数据作为样本,试用配对样本T检验,女性
男(n=18) 85 89 75 58 86 80 78 76 84 89 99 95 82 87 60 85
38
SPSS应用软件试验指导手册
人口的平均寿命是否确实比男性人口的平均寿命长,并给出差异的置信区间。(设α=0.05)
39
SPSS应用软件试验指导手册
试验4:方差分析
一、试验目标与要求
1.帮助学生深入了解方差及方差分析的基本概念,掌握方差分析的基本思想和原理
2.掌握方差分析的过程。
3.增强学生的实践能力,使学生能够利用SPSS统计软件,熟练进行单因素方差分析、两因素方差分析等操作,激发学生的学习兴趣,增强自我学习和研究的能力。
二、试验原理
在现实的生产和经营管理过程中,影响产品质量、数量或销量的因素往往很多。例如,农作物的产量受作物的品种、施肥的多少及种类等的影响;某种商品的销量受商品价格、质量、广告等的影响。为此引入方差分析的方法。
方差分析也是一种假设检验,它是对全部样本观测值的变动进行分解,将某种控制因素下各组样本观测值之间可能存在的由该因素导致的系统性误差与随即误差加以比较,据以推断各组样本之间是否存在显著差异。若存在显著差异,则说明该因素对各总体的影响是显著的。
方差分析有3个基本的概念:观测变量、因素和水平。观测变量是进行方差分析所研究的对象;因素是影响观测变量变化的客观或人为条件;因素的不同类别或不通取值则称为因素的不同水平。在上面的例子中,农作物的产量和商品的销量就是观测变量,作物的品种、施肥种类、商品价格、广告等就是因素。在方差分析中,因素常常是某一个或多个离散型的分类变量。
根据观测变量的个数,可将方差分析分为单变量方差分析和多变量方差分析;根据因素个数,可分为单因素方差分析和多因素方差分析。在SPSS中,有One-way ANOVA(单变量-单因素方差分析)、GLM Univariate(单变量多因素方差分析);GLM Multivariate (多变量多因素方差分析),不同的方差分析方法适用于不同的实际情况。本节仅练习最为常用的单因素单变量方差分析。
三、试验演示内容与步骤
单因素方差分析也称一维方差分析,对两组以上的均值加以比较。检验由单一因素影响的一个分析变量由因素各水平分组的均值之间的差异是否有统计意义。并可以进行两两组间均值的比较,称作组间均值的多重比较。主要采用One-way ANOVA过程。
采用One-way ANOVA过程要求:因变量属于正态分布总体,若因变量的分布明显 40
SPSS应用软件试验指导手册
是非正态,应该用非参数分析过程。若对被观测对象的试验不是随机分组的,而是进行的重复测量形成几个彼此不独立的变量,应该用Repeated Measure菜单项,进行重复测量方差分析,条件满足时,还可以进行趋势分析。
假设某汽车经销商为了研究东部、西部和中部地区市场上汽车的销量是否存在显著差异,在每个地区随机抽取几个城市进行调查统计,调查数据放置于数据文件“汽车销量调查.sav”中。在SPSS中试验该检验的步骤如下:
? 步骤1:选择菜单【分析】→【比较均值】→【单因素方差分析】,依次将观测变量销量移入因变量列表框,将因素变量地区移入因子列表框。
图4.1 One-Way ANOVA对话框
? 单击两两比较按钮,如图4.2,该对话框用于进行多重比较检验,即各因素水平下观测变量均值的两两比较。
方差分析的原假设是各个因素水平下的观测变量均值都相等,备择假设是各均值不完全相等。假如一次方差分析的结果是拒绝原假设,我们只能判断各观测变量均值不完全相等,却不能得出各均值完全不相等的结论。各因素水平下观测变量均值的更为细致的比较就需要用多重比较检验。
41
SPSS应用软件试验指导手册
图4.2 两两比较对话框
假定方差齐性选项栏中给出了在观测变量满足不同因素水平下的方差齐性条件下的多种检验方法。这里选择最常用的LSD检验法;未假定方差齐性选项栏中给出了在观测变量不满足方差齐性条件下的多种检验方法。这里选择Tamhane’s T2检验法;Significance level输入框中用于输入多重比较检验的显示性水平,默认为5%。
? 单击选项按钮,弹出options子对话框,如图所示。在对话框中选中描述性复选框,输出不同因素水平下观测变量的描述统计量;选择方差同质性检验复选框,输出方差齐性检验结果;选中均值图复选框,输出不同因素水平下观测变量的均值直线图。
? 在主对话框中点击ok按钮,可以得到单因素分析的结果。试验结果分析:表4.1给出了不同地区汽车销量的基本描述统计量以及95%的置信区间。
42
SPSS应用软件试验指导手册
图4.3 选项子对话框
表4.1 各个地区汽车销量描述统计量
Descriptives
表4.2给出了Levene方差齐性检验结果。从表中可以看到,Levene统计量对应的p值大于0.05,所以得到不同地区汽车销量满足方差齐性的结论。
表4.3是单因素方差分析,输出的方差分析表解释如下:总离差SST=19384.154,组间平方和SSR=6068.174,组内平方和或残差平方和SSE=13315.979,相应的自由度分别为25,2,23;组间均方差MSR=3034.087,组内均方差578.956,F=5.241,由于p=0.013<0.05说明在α=0.05显著性水平下,F检验是显著的。即认为各个地区的汽车销量并不完全相同。
43
SPSS应用软件试验指导手册
表4.3 单因素方差分析结果
ANOVA
表4.4 多重比较检验结果 Multiple Comparisons
如前所述,拒绝单因素方差分析原假设并不能得出各地区汽车销量均值完全不等的结论。各地区销量均值的两两比较要看表4.4所示的多重比较检验结果。表中上半部分为LSD检验结果,下半部分为Tamhane检验结果。由于方差满足齐性,所以这里应该看LSD检验结果。表中的Mean difference列给出了不同地区汽车销量的平均值之差。其中后面带“﹡”号的表示销量有显著差异,没有带“﹡”号的表示没有显著差异。可以看出,东部和西部汽车销量存在显著差异,而中部与东部、中部与西部汽车销量并没有什么显著差异。这一结论也可以从表中Sig列给出的p值大小得到印证。
四、备择试验
1. 用SPSS进行单因素方差分析。某个年级有三个小班,他们进行了一次数据考试,现从各班随机地抽取了一些学生,记录其成绩如表。原始数据文件保存为“数学考试成绩.sav”。试在显著性水平0.05下检验各班级的平均分数有无显著差异。
数学考试成绩表
44
SPSS应用软件试验指导手册
2.某学校给3组学生以3种不同方式辅导学习,一个学期后,学生独立思考水平提高的成绩如表所示。
学生独立思考水平提高的成绩
问:该数据中的因变量是什么?因素又是什么?如何建立数据文件?对该数据进行方差分析,检验3种方式的影响是否存在显著差异?
45
SPSS应用软件试验指导手册
试验5:相关分析与回归分析
一、试验目标与要求
本试验项目的目的是学习并使用SPSS软件进行相关分析和回归分析,具体包括:
(1) 皮尔逊pearson简单相关系数的计算与分析
(2) 学会在SPSS上实现一元及多元回归模型的计算与检验。
(3) 学会回归模型的散点图与样本方程图形。
(4) 学会对所计算结果进行统计分析说明。
(5) 要求试验前,了解回归分析的如下内容。
? 参数α、β的估计
? 回归模型的检验方法:回归系数β的显著性检验(t-检验);回归方程
显著性检验(F-检验)。
二、试验原理
1.相关分析的统计学原理
相关分析使用某个指标来表明现象之间相互依存关系的密切程度。用来测度简单线性相关关系的系数是Pearson简单相关系数。
2.回归分析的统计学原理
相关关系不等于因果关系,要明确因果关系必须借助于回归分析。回归分析是研究两个变量或多个变量之间因果关系的统计方法。其基本思想是,在相关分析的基础上,对具有相关关系的两个或多个变量之间数量变化的一般关系进行测定,确立一个合适的数据模型,以便从一个已知量推断另一个未知量。回归分析的主要任务就是根据样本数据估计参数,建立回归模型,对参数和模型进行检验和判断,并进行预测等。
线性回归数学模型如下:
yi??0??1xi1??2xi2????kxik??i
在模型中,回归系数是未知的,可以在已有样本的基础上,使用最小二乘法对回归系数进行估计,得到如下的样本回归函数:
????x???x?????x?e yi??01i12i2kiki
回归模型中的参数估计出来之后,还必须对其进行检验。如果通过检验发现模型有缺陷,则必须回到模型的设定阶段或参数估计阶段,重新选择被解释变量和解 46
SPSS应用软件试验指导手册
释变量及其函数形式,或者对数据进行加工整理之后再次估计参数。回归模型的检验包括一级检验和二级检验。一级检验又叫统计学检验,它是利用统计学的抽样理论来检验样本回归方程的可靠性,具体又可以分为拟和优度评价和显著性检验;二级检验又称为经济计量学检验,它是对线性回归模型的假定条件能否得到满足进行检验,具体包括序列相关检验、异方差检验等。
三、试验演示内容与步骤
1.连续变量简单相关系数的计算与分析
在上市公司财务分析中,常常利用资产收益率、净资产收益率、每股净收益和托宾Q值4个指标来衡量公司经营绩效。本试验利用SPSS对这4个指标的相关性进行检验。操作步骤与过程:
? 打开数据文件“上市公司财务数据(连续变量相关分析).sav”,依次选择“【分析】→【相关】→【双变量】”打开对话框如图,将待分析的4个指标移入右边的变量列表框内。其他均可选择默认项,单击ok提交系统运行。
图5.1 Bivariate Correlations对话框
结果分析:
表给出了Pearson简单相关系数,相关检验t统计量对应的p值。相关系数右上角 47
SPSS应用软件试验指导手册
有两个星号表示相关系数在0.01的显著性水平下显著。从表中可以看出,每股收益、净资产收益率和总资产收益率3个指标之间的相关系数都在0.8以上,对应的p值都接近0,表示3个指标具有较强的正相关关系,而托宾Q值与其他3个变量之间的相关性较弱。
表5.1 Pearson简单相关分析
Correlations
每股收益率
Pearson Correlation Sig. (2-tailed) N
净资产收益率
Pearson Correlation Sig. (2-tailed) N
资产收益率
Pearson Correlation Sig. (2-tailed) N
托宾Q值
Pearson Correlation Sig. (2-tailed) N
** Correlation is significant at the 0.01 level (2-tailed).
每股收益率
1 . 315 .877(**) .000 315 .824(**) .000 315 -.073 .199 315
净资产收益率 .877(**) .000 315 1 . 315 .808(**) .000 315 -.001 .983 315
资产收益率
.824(**) .000 315 .808(**) .000 315 1 . 315 .011 .849 315
托宾Q值
-.073 .199 315 -.001 .983 315 .011 .849 315 1 . 315
2.一元线性回归分析
实例分析:家庭住房支出与年收入的回归模型
在这个例子里,考虑家庭年收入对住房支出的影响,建立的模型如下:
yi????xi??i
其中,yi是住房支出,xi是年收入 线性回归分析的基本步骤及结果分析:
(1)绘制散点图 打开数据文件,选择【图形】-【旧对话框】-【散点/点状】,如图5.2所示。
48
SPSS应用软件试验指导手册
图5.2 散点图对话框
选择简单分布,单击定义,打开子对话框,选择X变量和Y变量,如图5.3所示。单击ok提交系统运行,结果见图5.4所示。
图5.3 Simple Scatterplot 子对话框
从图上可直观地看出住房支出与年收入之间存在线性相关关系。
49
SPSS应用软件试验指导手册
(2)简单相关分析
选择【分析】—>【相关】—>【双变量】,打开对话框,将变量“住房支出”与“年收入”移入variables列表框,点击ok运行,结果如表5.2所示。
表5.2 住房支出与年收入相关系数表
从表中可得到两变量之间的皮尔逊相关系数为0.966,双尾检验概率p值尾0.000<0.05,故变量之间显著相关。根据住房支出与年收入之间的散点图与相关分析显示,住房支出与年收入之间存在显著的正相关关系。在此前提下进一步进行回归分析,建立一元线性回归方程。 (3) 线性回归分析
步骤1:选择菜单“【分析】—>【回归】—>【线性】”,打开Linear Regression 对话框。将变量住房支出y移入Dependent列表框中,将年收入x移入Independents列表框中。在Method 框中选择Enter 选项,表示所选自变量全部进入回归模型。
50
SPSS应用软件试验指导手册
图5.5 Linear Regresssion对话框
步骤2:单击Statistics按钮,如图在Statistics子对话框。该对话框中设置要输出的统计量。这里选中估计、模型拟合度复选框。
51
SPSS应用软件试验指导手册
图5.6 Statistics子对话框
? 估计:输出有关回归系数的统计量,包括回归系数、回归系数的标准差、
标准化的回归系数、t统计量及其对应的p值等。
? 置信区间:输出每个回归系数的95%的置信度估计区间。
? 协方差矩阵:输出解释变量的相关系数矩阵和协差阵。
? 模型拟合度:输出可决系数、调整的可决系数、回归方程的标准误差、
回归方程F检验的方差分析。
步骤3:单击绘制按钮,在Plots子对话框中的标准化残差图选项栏中选中正态概率图复选框,以便对残差的正态性进行分析。
图5.7 plots子对话框
步骤4:单击保存按钮,在Save子对话框中残差选项栏中选中未标准化复选框,这样可以在数据文件中生成一个变量名尾res_1 的残差变量,以便对残差进行进一步分析。
52
SPSS应用软件试验指导手册
图5.8 Save子对话框
其余保持Spss默认选项。在主对话框中单击ok按钮,执行线性回归命令,其结果如下:
表5.3给出了回归模型的拟和优度(R Square)、调整的拟和优度(Adjusted R Square)、估计标准差(Std. Error of the Estimate)以及Durbin-Watson统计量。从结果来看,回归的可决系数和调整的可决系数分别为0.934和0.93,即住房支出的90%以上的变动都可以被该模型所解释,拟和优度较高。
表5.4给出了回归模型的方差分析表,可以看到,F统计量为252.722,对应的p值为0,所以,拒绝模型整体不显著的原假设,即该模型的整体是显著的。 表5.5给出了回归系数、回归系数的标准差、标准化的回归系数值以及各个回归系数的显著性t检验。从表中可以看到无论是常数项还是解释变量x,其t统计量对应的p值都小于显著性水平0.05,因此,在0.05的显著性水平下都通过了t检验。变量x的回归系数为0.237,即年收入每增加1千美元,住房支出就增加0.237千美元。
表5.3 回归模型拟和优度评价及Durbin-Watson检验结果
Model Summary(b)
b Dependent Variable:住房支出(千美元)
表5.4 方差分析表
b Dependent Variable: 住房支出(千美元)
表5.5 回归系数估计及其显著性检验
为了判断随机扰动项是否服从正态分布,观察图5.9所示的标准化残差的P-P图,可以发现,各观测的散点基本上都分布在对角线上,据此可以初步判断残差服从正
53
SPSS应用软件试验指导手册
态分布。
为了判断随机扰动项是否存在异方差,根据被解释变量y与解释变量x的散点图,如图5.4所示,从图中可以看到,随着解释变量x的增大,被解释变量的波动幅度明显增大,说明随机扰动项可能存在比较严重的异方差问题,应该利用加权最小二乘法等方法对模型进行修正。
四、备择试验
现有1987~2003年湖南省全社会固定资产投资总额NINV和GDP两个指标的年度数据,见下表。试研究全社会固定资产投资总额和GDP的数量关系,并建立全社会固定资产投资总额和GDP之间的线性回归方程。
54
SPSS应用软件试验指导手册
55
SPSS应用软件试验指导手册
附录:《管理统计学》上机试验报告格式
试验名称: 成绩: