hadoop-core-1.0.2-SNAPSHOT.jar
如果不编译hadoop的core,将使用到hadoop-core-1.0.2-SNAPSHOT.jar的地方路径定位为%HDOOP_HOME%/hadoop-core-1.0.1.jar的绝对路径
5.4. 从已编译好的hadoop进行eclipse-plugin编译
2. 在hadoop-1.0.1/src/contrib/eclipse-plugin/build.xml中添加如下内容 <property name="eclipse.home" value="/opt/eclipse"/> <property name="version" value="1.0.2-SNAPSHOT"/>
<importfile="../build-contrib.xml"/>
3. 在hadoop-1.0.1/src/contrib/eclipse-plugin/build.xml中添加如下内容 <mkdir dir="${build.dir}/lib"/>
<copy file="${hadoop.root}/build/hadoop-core-${version}.jar" tofile="${build.dir}/lib/hadoop-core.jar" verbose="true"/>
<copy file="${hadoop.root}/build/ivy/lib/Hadoop/common/commons-cli-${commons-cli.version}.jar" todir="${build.dir}/lib" verbose="true"/> <copy file="${hadoop.root}/lib/commons-lang-2.4.jar" todir="${build.dir}/lib" verbose="true"/>
<copy file="${hadoop.root}/lib/commons-configuration-1.6.jar" todir="${build.dir}/lib" verbose="true"/> <copy file="${hadoop.root}/lib/jackson-mapper-asl-1.8.8.jar" todir="${build.dir}/lib" verbose="true"/>
<copy file="${hadoop.root}/lib/jackson-core-asl-1.8.8.jar" todir="${build.dir}/lib" verbose="true"/>
<copy file="${hadoop.root}/lib/commons-httpclient-3.0.1.jar" todir="${build.dir}/lib" verbose="true"/>
4. New-->"java project
Project name:commontest
Location:/opt/hadoop-1.0.1 (hadoop解压路径)
5. 创建项目后进入项目属性(Project?Properties)
6. 进入Builders,默认只有Java Builder
7. 将
Java Builder的√去掉,新建Ant Builder
8. Buildfile指向hadoop-1.0.1/src/contrib/eclipse-plugin/build.xml
9. Base Directory指向hadoop-1.0.1/src/contrib/eclipse-plugin/
10. 最终效果如下图
11. 在执行前可以修改ant为系统路径,参见可选步骤。
12. 确定后执行Project?build project。同时把该菜单下的自动编译(Build Automatically)
的√去掉。 13. 正确执行后在hadoop-1.0.1/build/contrib/eclipse-plugin下面会有一个jar文件生成
hadoop-eclipse-plugin-1.0.2-SNAPSHOT.jar
14. 将HADOOP_HOME/lib目录下的
commons-configuration-1.6.jar ,
commons-httpclient-3.0.1.jar ,
commons-lang-2.4.jar ,
jackson-core-asl-1.8.8.jar jackson-mapper-asl-1.8.8.jar
等5个包复制到hadoop-eclipse-plugin-1.0.2-SNAPSHOT.jar的lib目录下
15. 修改该包META-INF目录下的MANIFEST.MF,将classpath修改为以下内容: Bundle-ClassPath:
classes/,lib/hadoop-core.jar,lib/commons-lang-2.4.jar,lib/commons-configuration-1.6.jar,lib/jackson-mapper-asl-1.8.8.jar,lib/jackson-core-asl-1.8.8.jar,lib/commons-httpclient-3.0.1.jar
注:RedHat中修改包中内容需要将文件拖出来修改后再拖进去
5.5. Eclipse-Plugin配置
1. 将上一步生成的jar复制到Eclipse的plugins目录下,重启Eclipse
注:如果之前已经将未配置好的hadoop-eclipse-plugin-1.0.2-SNAPSHOT.jar复制到该目录下,那么需要将原先插件删除,开启一个Eclipse,然后关闭,再将新插件复制到该目录下。
2. Eclipse中打开Window-->Preferens,发现Hadoop Map/Reduce选项,在这个选项里配置Hadoop installation directory。
3. 配置Map/Resuce Locations:
在Window-->Show View->other...,在MapReduce Tools中选择Map/Reduce Locations。
在Map/Reduce Locations(Eclipse界面的正下方)中新建一个Hadoop Location。 在这个View中,点击鼠标右键-->New Hadoop Location。在弹出的对话框中你需要配置:
Location Name :此处为参数设置名称,可以任意填写。
Map/Reduce Master (此处为Hadoop集群的Map/Reduce地址, 应该和mapred-site.xml中的.mapred.job.tracker设置相同)
Host: localhost
port: 9001
DFS Master (此处为Hadoop的master服务器地址,应该和core-site.xml中的 fs.default.name设置相同).
Host: localhost
Port: 9000
设置完成后,点击Finish应用设置
6. Hive配置
6.1. 准备
hive不支持用insert语句一条一条的进行插入操作,也不支持update操作。 数据是以load的方式加载到建立好的表中。数据一旦导入就不可以修改。
即只支持文件形式更新或者将查询结果插入到数据库中 获得Hive
wget
或者
wget
解压并安装到/opt/hadoop-1.0.1/hive-0.8.1
下文以0.8.1为例进行安装
6.2. Hive环境参数
在/etc/profile文件尾部内容,添加 export HADOOP_HOME=/opt/hadoop-1.0.1
PATH=$HADOOP_HOME/bin:$PATH
export HIVE_HOME=$HADOOP_HOME/hive-0.8.1
export PATH=$HIVE_HOME/bin:$PATH
6.3. Hive配置
6.3.1. site.xml
1.将hive-0.8.1目录下/conf/hive-env.sh.template中的HADOOP_HOME为改实际的Hadoop安装目录 # Set HADOOP_HOME to point to a specific hadoop install directory
HADOOP_HOME=/opt/hadoop-1.0.1
2.将conf/hive-env.sh.template复制并命名为hive-env.sh,再增加执行权限
6.3.2. 在HDFS中创建Hive目录
在HDFS中创建/tmp和/user/hive/warehouse并设置权限:
提示:记得先打开HDFS(执行start-all.sh);
hadoop fs -mkdir /tmp
hadoop fs -mkdir /user/hive/warehouse hadoop fs -chmod g+w /tmp
hadoop fs -chmod g+w /user/hive/warehouse
将$HIVE_HOME/conf/hive-default.xml.template复制两份,分别命名为hive-default.xml(用于保留默认配置)和
hive-site.xml(用于个性化配置,可覆盖默认配置)
提示:
/tmp和/user/hive/warehouse这两个路径是在hive-site.xml中的
ive.metastore.warehouse.dir属性和hive.exec.scratchdir属性指定的。
6.4. 运行hive
配置完环境变量记得注销再登陆
执行hive后看到如下图所示的hive>即安装正确
如果出现如下错误
6.5. 测试
执行:
show tables;
正确界面
如果出现如下错误提示,请将$HADOOP_HOME/build这个文件夹移到别的地方后重新进入Hive FAILED: Error in metadata: javax.jdo.JDOFatalInternalException: Unexpected exception caught. NestedThrowables:
java.lang.reflect.InvocationTargetException FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask
6.5.1. 测试MapReduce
1.在hive>命令提示符下执行如下语句,创建pokes表
CREATE TABLE pokes (foo INT, bar STRING);
2.执行如下语句,将内部测试数据载入pokes表中 LOAD DATA LOCAL INPATH '/opt/hadoop-1.0.1/hive-0.8.1/examples/files/kv1.txt' OVERWRITE INTO TABLE pokes;
3.执行如下语句
select foo from pokes;
如果最终能正确显示一堆的数字,表明Hive结合MapReduce使用没问题。 参考:https://cwiki.apache.org/confluence/display/Hive/GettingStarted
6.6. 退出
在hive的Shell中输入exit;
7. Hive-MySql配置
7.1. 问题引入
按照第7步安装的元数据保持在内嵌的数据库Derby中,只能允许一个会话连接,如果要支持多用户多会话,则需要一个独立的元数据库,目前比较流行的是使用MySQL
7.2. 安装mysql并启动对应服务
yum install mysql
yum install mysql-server
yum install mysql-devel
service mysqld start
提示:yum配置参见附录1
7.3. 为Hive建立相应的MySQL帐号,并赋予足够的权限
1.mysql的root命令行:mysql -uroot -p
2.创建hive数据库:create database hive;
3.创建用户hive,它只能从localhost连接到数据库并可以连接到wordpress数据库 grant all on hive.* to hive@localhost identified by '123456';
7.4. 修改配置文件hive-site.xml 将在Hive的conf目录下的配置文件hive-site.xml中对应内容修改为如下 <property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value> <description>JDBC connect string for a JDBC metastore</description>
文档控制
修改类型:A——加工
M——修改 D——删除 黑色颜色字体为系统输出或已存在内容
绿色颜色字体为输入或修改的内容
紫色字体为提示信息或注意信息
红色字体为需要注意的路径问题
目录
1.
2.
3. 使用的软件版本 ....................................................................................................................... 4 安装好虚拟机及创建linux系统 ............................................................................................. 4 基本配置 ................................................................................................................................... 4
3.1. ssh的安装设置 ............................................................................................................ 4
3.1.1. 由于Hadoop用ssh 通信,先进行免密码登录设定 .................................... 4
3.1.2. 完成后请登入确认不用输入密码(第一次登入需输入密码,第二次就可以
直接登入到系统) ........................................................................................................... 4
3.1.3. Agent admitted failure to sign using the key错误 ............................................ 4
3.1.4. 成功界面 ........................................................................................................... 4
3.2. 安装与配置JAVA .......................................................................................................... 4
Hadoop配置——伪分布模式 .................................................................................................. 5
4.1. Hadoop环境参数 ......................................................................................................... 5
4.2. hadoop配置 ................................................................................................................. 5
4.3. Hadoop运行 ................................................................................................................. 6
4.3.1. 格式化分布式文件系统 ................................................................................... 6
4.3.2. 启动hadoop守护进程:................................................................................. 6
4.3.3. 复制文件 ........................................................................................................... 6
4.4. 运行WordConut实例: .............................................................................................. 7
4.5. 停止Hadoop守护进程。 ............................................................................................ 8
Eclipse-plugin编译 ................................................................................................................... 8
4. 5.
6.
7.
8.
9. 5.1. 注意点 ........................................................................................................................... 8 5.2. 可选步骤:使用系统自带的ant................................................................................. 8 5.3. 可选步骤:编译hadoop的core ................................................................................ 8 5.4. 从已编译好的hadoop进行eclipse-plugin编译 ........................................................ 9 5.5. Eclipse-Plugin配置 ..................................................................................................... 10 Hive配置 ................................................................................................................................ 10 6.1. 注意事项 ..................................................................................... 错误!未定义书签。 6.2. 获得Hive .................................................................................................................... 10 6.3. Hive环境参数............................................................................................................. 11 6.4. Hive配置 .................................................................................................................... 11 6.5. 创建Hive文件路径 .................................................................................................... 11 6.6. 运行hive ..................................................................................................................... 11 6.7. 测试 ............................................................................................................................. 11 6.8. 测试MapReduce ........................................................................................................ 12 Hive-MySql配置 ..................................................................................................................... 12 7.1. 问题引入 ..................................................................................................................... 12 7.2. 安装mysql并启动对应服务 ..................................................................................... 12 7.3. 为Hive建立相应的MySQL帐号,并赋予足够的权限 .......................................... 12 7.4. 修改配置文件hive-site.xml ....................................................................................... 12 7.5. 把MySQL的JDBC驱动包复制到Hive的lib目录下。 .......................................... 13 7.6. 重新运行hive ............................................................................................................. 13 7.7. 查看一下元数据的效果。 ......................................................................................... 13 HBase配置.............................................................................................................................. 13 8.1. 修改打开文件数目的限制 ......................................................................................... 13 8.2. 设置系统允许运行的最大进程数目 ......................................................................... 14 8.3. 获得HBase .................................................................................................................. 14 8.4. HBase环境参数 .......................................................................................................... 14 8.5. HBase配置 .................................................................................................................. 14 8.5.1. 修改HBase路径下的conf/hbase-site.xml文档 ........................................... 14 8.5.2. 修改HBase路径下的conf/hbase-env.sh文档 ............................................. 15 8.6. 修改hadoop的配置文件 .......................................................................................... 15 8.6.1. 启动durable sync功能 .................................................................................. 15 8.6.2. 配置HDFS一次最多可以提供的文件数上限:........................................... 15 8.7. 启动HBase .................................................................................................................. 15 8.8. 测试 ............................................................................................................................. 16 8.9. 重启后无法停止HBase问题 ..................................................................................... 17 错误总结 ................................................................................................................................. 17
9.1. 命令行中执行错误 ..................................................................................................... 17
9.1.1. Agent admitted failure to sign using the key ................................................... 17
9.1.2. WARN hdfs.DFSClient: DataStreamer Exception:
org.apache.hadoop.ipc.RemoteException ...................................................................... 17
9.1.3. org.apache.hadoop.dfs.SafeModeException: Cannot delete
/user/hadoop/input. Name node is in safe mode........................................................... 17
9.1.4. ERROR security.UserGroupInformation: PriviledgedActionException ............. 18
9.1.5. Exception in thread "main" java.io.IOException: Error opening job jar:
hadoop-examples-1.0.1.jar ............................................................................................. 18
9.1.6. INFO ipc.Client: Retrying connect to server: localhost/127.0.0.1:9000. Already
tried 9 time(s). ................................................................................................................. 18
9.2. Eclipse插件错误 ......................................................................................................... 18
9.2.1. Call to localhost/127.0.0.1:9000 failed on connection .................................... 18
9.3. Hive错误 .................................................................................................................... 19
9.3.1. FAILED: Error in metadata ............................................................................... 19
10. 附录1 yum配置 ............................................................................................................. 19
10.1. 更新配置文件 ......................................................................................................... 19
11. 核心参考资料 ................................................................................................................. 21
12. 其他 ................................................................................................................................. 21
1. 使用的软件版本
(1)VMware8.0.0.exe
(2)hadoop-1.0.1.tar.gz
(3)jdk-6u32-linux-i586.bin
(4)rhel-server-5.4-i386-dvd.iso 也可以使用 ubuntu-12.04-desktop-i386.iso
(5)Eclipse 3.7(必须)
(6)hive-0.8.1
2. 安装好虚拟机及创建linux系统
3. 基本配置
3.1. ssh的安装设置
3.1.1. 由于Hadoop用ssh 通信,先进行免密码登录设定
注意:此处免密码登陆设定为root用户使用,伪分布模式就用root用户就好
非root用户的免密码登陆见全分布配置
$ apt-get install ssh (Redhat系统默认已经安装,略过)
$ ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
$ ssh localhost
3.1.2. 完成后请登入确认不用输入密码(第一次登入需输入密码,第二次就可以直接登入
到系统)
~$ ssh localhost
~$ exit
~$ ssh localhost
~$ exit
3.1.3. Agent admitted failure to sign using the key错误
前提:在输入ssh localhost
错误:命令行提示Agent admitted failure to sign using the key
解决:
1.
输入ps -Af|grep agent查看有无ssh-agent有无运行
2. 若没有在~/.ssh目录下执行
~/.ssh$ ssh-agent
~/.ssh$ ssh-add id_rsa
再次返回第二步
3.1.4. 成功界面
3.2. 安装与配置JAVA
安装完毕java后配置系统路径
在/etc/profile文件尾部内容,添加
JAVA_HOME=/opt/java/jdk1.6.0_32 PATH=$JAVA_HOME/bin:$PATH
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export JAVA_HOME
export PATH
export CLASSPATH
4. Hadoop配置——伪分布模式
4.1. 准备
1、将安装包hadoop-1.0.1.tar.gz 拷贝至 /opt 下
2、解压包:tar -zvxf hadoop-1.0.1.tar.gz
4.2. Hadoop环境参数
1、配置Hadoop环境参数: 在/etc/profile文件尾部内容,添加
export HADOOP_HOME=/opt/hadoop-1.0.1
PATH=$HADOOP_HOME/bin:$PATH 2、注销用户并重登陆(重启也可以)(此为Ubuntu下命令)
sudo skill -kill clcnsy
重启后输入
hadoop version
出现版本信息 安装完毕
3、编辑/opt/hadoop-1.0.1/conf/hadoop-env.sh文件将JAVA_HOME指定为本机路径
# The java implementation to use. Required.
export JAVA_HOME=/opt/java/jdk1.6.0_32
4.3. hadoop配置
将hadoop-1.0.1conf下面的文件进行更新
1)core-site.xml文档内容
<configuration> <property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value> <description>The name of the default file system.A URI whose scheme and authority determine the FileSystem implementation.
</description>
</property>
<!--make sure this tmp directory will not be deleted when reboot PC-->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/clcnsy/hadoopdata/tmp</value>
<description>A base for other temporary directories.</description>
</property> </configuration>
2)hdfs-site.xml文档内容:
<configuration> <!--make sure the value less than then the number of cluster machines--> <property>
<name>dfs.replication</name>
<value>1</value>
<description>The actual number of replication can be specified when the file is created.
</description>
</property>
<property>
<name>dfs.data.dir</name>
<value>/home/clcnsy/hadoopdata/hdfs/data</value>
<final>true</final>
</property>
<property>
<name>dfs.name.dir</name>
<value>/home/clcnsy/hadoopdata/hdfs/name</value>
<final>true</final>
</property>
</configuration>
3)mapred-site.xml文档内容: <configuration>
<property>
<name>mapred.job.tracker</name>
<value>localhost:9001</value>
<description>The host and port that the MapReduce job tracker runs at. </description> </property>
</configuration>
4.4. Hadoop运行
4.4.1. 格式化分布式文件系统
hadoop namenode -format
4.4.2. 启动hadoop守护进程:
start-all.sh
4.4.3. 复制文件
// 将conf中的内容复制到hadoop中的input文件夹中
hadoop fs -put conf input
正常执行后输出为
如果出现下面异常,执行关闭防火墙操作
WARN hdfs.DFSClient: DataStreamer Exception: org.apache.hadoop.ipc.RemoteException sudo ufw disable
stop-all.sh
start-all.sh
hadoop fs -put conf input
如果出现下面异常,执行关闭安全模式操作
org.apache.hadoop.dfs.SafeModeException: Cannot delete /user/hadoop/input. Name node is in safe mode hadoop dfsadmin -safemode leave
详细:
4.5. 测试WordConut实例:
(1)先在~/test中建立两个输入文件file01 和file02:
echo “Hello World Bye World” > file01 echo “Hello Hadoop Goodbye Hadoop” > file02
(2)在~/中运行
hadoop fs -put test input
(3)执行wordcount:
hadoop jar /opt/hadoop-1.0.1/hadoop-examples-1.0.1.jar wordcount input output
(4)完成之后,查看结果:
hadoop fs -cat output/part-r-00000
如出现下面错误,表示output目录已经存在,需要更变output目录
ERROR security.UserGroupInformation: PriviledgedActionException
如出现下面异常,表示jar包指定错误,一般是由路径问题引起,可以采用绝对路径解决
Exception in thread "main" java.io.IOException: Error opening job jar: hadoop-examples-1.0.1.jar
(5)复制到本地查看:
hadoop fs -get output output
第3步运行过程截图:
第4步执行输出截图:
另一种方式(未测试)
(1)先在本地磁盘建立两个输入文件file01 和file02:
$ echo “Hello World Bye World” > file01
$ echo “Hello Hadoop Goodbye Hadoop” > file02
(2)在hdfs 中建立一个input 目录:$ hadoop fs –mkdir input
(3)将file01 和file02 拷贝到hdfs 中:
$ hadoop fs –copyFromLocal /home/clcnsy/soft/file0* input
(4)执行wordcount:
$ hadoop jar hadoop-0.20.1-examples.jar wordcount input output
(5)完成之后,查看结果:
$ hadoop fs -cat output/part-r-00000
4.6. 停止Hadoop进程。
stop-all.sh
5. Eclipse-plugin编译
5.1. 注意点
1. 务必使用Eclipse3.7的版本
2. 务必使用JDK1.6环境
3. 以下内容在hadoop-1.0.1下测试通过
5.2. 可选步骤:使用系统自带的ant
1. 此步骤目的是为了在编译时候不下载ant而使用系统自带的
2. 安装ant
sudo adp-get insatall ant
3. 配置ant的PATH路径 ANT_HOME=/usr/share/ant
PATH=$ANT_HOME/bin:$PATH
4. 将有用到ant的代码按照如下步骤修改(根据实际不同build.xml都需要单独修改)
4.1注释掉下面代码内容
target name="ivy-download" description="To download ivy" unless="offline">
<get src="${ivy_repo_url}" dest="${ivy.jar}" usetimestamp="true"/>
</target>
4.2在build.xml中搜索ivy-download,将搜索到的内容去掉。
原则上只会在这里出现
<target name="ivy-init-antlib" depends="ivy-download,ivy-init-dirs,ivy-probe-antlib"/>
5. 注销并重新登录
5.3. 可选步骤:编译hadoop的core
1. 步骤参见8.4的第三步至第八步,下面步骤需要此步骤提供的
</property> <property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description> </property> <property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
<description>username to use against metastore database</description> </property> <property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
<description>password to use against metastore database</description>
</property>
7.5. 把MySQL的JDBC驱动包复制到Hive的lib目录下。
在搭建环境时候我使用的是163的yum源。下载的mysql版本为
mysql Ver 14.12 Distrib 5.0.95, for redhat-linux-gnu (i686) using readline 5.1
在这个版本下可以使用如下的mysql驱动
mysql-connector-java-5.0.8-bin.jar
从http://downloads.mysql.com/archives/mysql-connector-java-5.0/mysql-connector-java-5.0.8.tar.gz下载
7.6. 重新运行hive
执行:
show tables;
如果不报错,表明基于独立元数据库的Hive已经安装成功了。
7.7. 查看一下元数据的效果。
在Hive上建立数据表:
CREATE TABLE my(id INT,name string) ROW FORMAT DELIMITED FIELDS TERMINATED BY
't';
show tables;
select name from my;
然后以刚刚建立的hive帐号登录MySQL查看元数据信息。
mysql> use hive
mysql> show tables;
mysql> select * from TBLS;
在TBLS中可以看到Hive表的元数据。
参考http://www.lamfire.com/?p=55
8. HBase配置
8.1. 准备
8.1.1. 修改打开文件数目的限制
默认时候的值为1024,我们需要修改它。
在/etc/security/limits.conf增加一行:
root - nofile 32768
注释:root为运行hadoop的用户名,-表示同时增加hard和soft的值
在注销后重新登录用以下命令检查是否修改了改值
ulimit -n
8.1.2. 设置系统允许运行的最大进程数目
在相同的文件中加入:
root - nproc 32000
在注销后重新登录用以下命令检查是否修改了改值
ulimit -u
8.2. 获得HBase
wget http://apache.etoak.com/hbase/hbase-0.92.0/hbase-0.92.0.tar.gz 解压并安装到/opt/hadoop-1.0.1/hbase-0.92.0
提示:可以考虑用下载器下载,这个包约34M
下文以0.92.0为例进行安装
8.3. HBase环境参数 在/etc/profile文件尾部下添加如下两行
export HBASE_HOME=$HADOOP_HOME/hbase-0.92.0
PATH=$HBASE_HOME/bin:$PATH
8.4. HBase配置
8.4.1. 修改HBase路径下的conf/hbase-site.xml文档
<configuration>
<property> <name>hbase.rootdir</name>
<value>hdfs://localhost:9000/hbase</value>
<description>此参数执行了region服务器的位置,即数据存放位置。
</description>
</property> <property>
<name>dfs.replication</name>
<value>1</value>
<description>此参数指定了Hlog和Hfile的副本个数,此参数值不能大于
HDFS节点个数。伪分布模式下DataNode只有一台,因此此参数应设置为
1</description>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
<description>The mode the cluster will be in. Possible values are
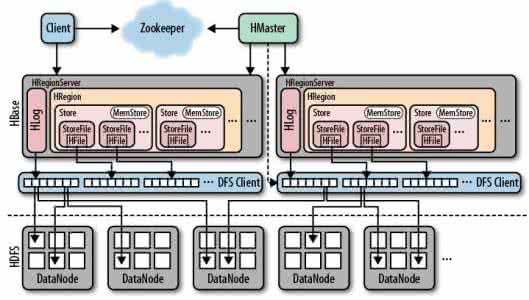
false: standalone and pseudo-distributed setups with managed
Zookeeper
true: fully-distributed with unmanaged Zookeeper Quorum (see
hbase-env.sh)
</description>
</property>
<property>
<name>dfs.support.append</name>
<value>true</value>
<description>此参数启动durable sync功能,使得HBase不再丢失数据,
</description> </property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/home/clcnsy/zookeeper</value> <description>Property from ZooKeeper's config zoo.cfg.
The directory where the snapshot is stored.
</description>
</property>
</configuration>
8.4.2. 修改HBase路径下的conf/hbase-env.sh文档
1.配置JAVA路径和hdfs-site路径
# The java implementation to use. Java 1.6 required.
export JAVA_HOME=/opt/java/jdk1.6.0_32
# Extra Java CLASSPATH elements. Optional.
export HBASE_CLASSPATH=/opt/hadoop-1.0.1/conf/hdfs-site.xml
8.5. Hadoop配置
8.5.1. 启动durable sync功能
打开$HADOOP_HOME/conf/hdfs-site.xml,添加如下内容
<configuration>
……
<property>
<name>dfs.support.append</name>
<value>true</value>
<description>此参数启动durable sync功能,使得HBase不再丢失数据,
</description>
</property> ……
</configuration>
8.5.2. 配置HDFS一次最多可以提供的文件数上限:
打开$HADOOP_HOME/conf/hdfs-site.xml,添加如下内容
<property>
<name>dfs.datanode.max.xcievers</name>
<value>4096</value>
</property>
8.6. 启动HBase
上一步骤配置的hbase.rootdir需要手工创建
运行hadoop后执行
hadoop fs -mkdir /hbase
start-hbase.sh
8.7. 测试 绿色部分为输入命令
hbase(main):004:0> create 'test','c1','c2' 0 row(s) in 1.2110 seconds
hbase(main):005:0> list
TABLE test 1 row(s) in 0.1140 seconds
hbase(main):009:0> put 'test','r1','c1:1','value1-1/1' 0 row(s) in 0.0990 seconds
hbase(main):010:0> put 'test','r1','c1:2','value1-1/2' 0 row(s) in 0.0070 seconds
hbase(main):011:0> put 'test','r1','c1:3','value1-1/3' 0 row(s) in 0.0080 seconds
hbase(main):012:0> put 'test','r2','c2:1','value1-2/1' 0 row(s) in 0.0150 seconds
hbase(main):013:0> put 'test','r2','c2:2','value1-2/2' 0 row(s) in 0.0380 seconds
hbase(main):015:0> scan 'test'
ROW COLUMN+CELL r1 column=c1:1, timestamp=1336582660190, value=value1-1/1 r1 column=c1:2, timestamp=1336582667819, value=value1-1/2 r1 column=c1:3, timestamp=1336582676155, value=value1-1/3 r2 column=c2:1, timestamp=1336582689071, value=value1-2/1 r2 column=c2:2, timestamp=1336582692972, value=value1-2/2 2 row(s) in 0.2340 seconds
hbase(main):017:0> disable 'test'
0 row(s) in 2.9360 seconds
hbase(main):018:0> drop 'test'
0 row(s) in 2.6060 seconds
hbase(main):019:0> list
TABLE 0 row(s) in 0.1240 seconds
8.8. 重启后无法停止HBase问题
原先配置时候在12.5.1的配置内容中hbase.cluster.distributed的属性值为false,即表明HBase运行于伪分布模式下,很容易出现重启HBase后就无法stop;
可能由于版本关系,尽管网络上尽管有很多关于这个的问题的报告,但是没有找到合适的。
分析了按照如下流程所记录的任务日志:启动?关闭(成功)?启动?关闭(失败);发现其中有一个ERROR。但是该ERROR没有找到合适的解决方式
目前的解决方式是将HBase运行模式改成全分布模式,该问题不会出现。即将hbase.cluster.distributed的值改为true。
注:目前12.5.1的配置已经是true了,如果按照前面步骤执行应该不会出现这个问题。
9. 错误总结
9.1. 命令行中执行错误
9.1.1. Agent admitted failure to sign using the key
前提:在输入ssh localhost
错误:提示如标题
解决:
1. 输入ps -Af|grep agent查看有无ssh-agent有无运行
2. 若没有在~/.ssh目录下执行 ~/.ssh$ ssh-agent
~/.ssh$ ssh-add id_rsa
3. 重新执行ssh localhost
9.1.2. WARN hdfs.DFSClient: DataStreamer Exception: org.apache.hadoop.ipc.RemoteException
前提:输入hadoop fs -put conf input
注意:该错误一般只在Ubuntu下产生
错误:提示如标题
解决:
1. 2.
3. 4. sudo ufw disable stop-all.sh start-all.sh hadoop fs -put conf input
9.1.3. org.apache.hadoop.dfs.SafeModeException: Cannot delete /user/hadoop/input. Name
node is in safe mode
前提:输入hadoop fs -put conf input
错误:提示如标题
解决:退出hadoop的安全模式
1. hadoop dfsadmin -safemode leave
2. 详细:
9.1.4. ERROR security.UserGroupInformation: PriviledgedActionException
前提:输入hadoop jar /opt/hadoop-1.0.1/hadoop-examples-1.0.1.jar wordcount input output 错误:提示如标题
原因:output目录以及存在
解决:更改输出目录
9.1.5. Exception in thread "main" java.io.IOException: Error opening job jar:
hadoop-examples-1.0.1.jar
前提:输入hadoop jar /opt/hadoop-1.0.1/hadoop-examples-1.0.1.jar wordcount input output 错误:提示如标题
原因:
字面含义是找不到main方法,一般来说出现该问题是jar包指定错误
如果直接在某个非hadoop目录下运行下面命令就会出现该问题
hadoop-examples-1.0.1.jar wordcount input output
解决:采用绝对路径制定jar包解决
9.1.6. INFO ipc.Client: Retrying connect to server: localhost/127.0.0.1:9000. Already tried 9
time(s).
前提:执行完shart-all.sh
错误:提示如标题
解决:执行下面命令,关闭安全模式
hadoop dfsadmin -safemode leave
9.2. Eclipse插件错误
9.2.1. Call to localhost/127.0.0.1:9000 failed on connection
前提:安装并配置好Eclipse插件在左侧显示DFS Locations内容
操作:打开点开下图“1”的左侧三角
出现Call to localhost/127.0.0.1:9000 failed on connection
错误可能1:hadoop的HDFS没有开启
执行start-all.sh
错误可能2:hadoop出于安全模式
执行下面命令,关闭安全模式
hadoop dfsadmin -safemode leave
错误可能3:如果弹出对话框提示如下内容
An internal error occurred during:
"Connecting to DFS localhost".org/apache/commons/configuration/Configuration
紫色的第二行内容可能会有所不同,导致该问题的原因是Eclipse的jar包中缺少必要的jar包,解决方法参考8.4.14以后内容,同时按照9.1中提示的内容进行操作。
9.3. Hive错误
9.3.1. FAILED: Error in metadata 完整错误:
FAILED: Error in metadata: javax.jdo.JDOFatalInternalException: Unexpected exception caught. NestedThrowables:
java.lang.reflect.InvocationTargetException FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask
前提:安装好Hive后进入Hive命令行,执行show tables;操作
操作:将$HADOOP_HOME/build这个文件夹移到别的地方或删除
10. 附录1 yum配置
使用以下配置的前提是你在安装RedHat时候没有输入序列号
以下配置在RedHat 5.4下测试通过
10.1. 更新配置文件
1.进入目录/etc/yum.repos.d/ 默认情况下会有rhel-debuginfo.repo这个配置文件
将它改名为rhel-debuginfo.repo.bak
2.下载网易默认配置文件
wget http://mirrors.163.com/.help/CentOS-Base-163.repo
3.修改配置文件
使用vi或gedit将 $releasever 替换成5
4.清理并重新生成yum缓存
yum clean metadata
yum makecache
提示:如果修改后还无法执行yum,请将配置文件中内容更改为如下内容。
# CentOS-Base.repo
#
# The mirror system uses the connecting IP address of the client and the
# update status of each mirror to pick mirrors that are updated to and
# geographically close to the client. You should use this for CentOS updates # unless you are manually picking other mirrors.
#
# If the mirrorlist= does not work for you, as a fall back you can try the
# remarked out baseurl= line instead.
#
#
[base]
name=CentOS-$releasever - Base - 163.com
mirrorlist=http://mirrorlist.centos.org/?release=5&arch=$basearch&repo=os baseurl=http://mirrors.163.com/centos/5/os/$basearch/
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-5
#released updates
[updates]
name=CentOS-$releasever - Updates - 163.com
mirrorlist=http://mirrorlist.centos.org/?release=5&arch=$basearch&repo=updates baseurl=http://mirrors.163.com/centos/5/updates/$basearch/
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-5
#packages used/produced in the build but not released
[addons]
name=CentOS-$releasever - Addons - 163.com
mirrorlist=http://mirrorlist.centos.org/?release=5&arch=$basearch&repo=addons baseurl=http://mirrors.163.com/centos/5/addons/$basearch/
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-5
#additional packages that may be useful
[extras]
name=CentOS-$releasever - Extras - 163.com
mirrorlist=http://mirrorlist.centos.org/?release=5&arch=$basearch&repo=extras baseurl=http://mirrors.163.com/centos/5/extras/$basearch/
gpgcheck=1
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-5
#additional packages that extend functionality of existing packages
[centosplus]
name=CentOS-$releasever - Plus - 163.com
mirrorlist=http://mirrorlist.centos.org/?release=5&arch=$basearch&repo=centosplus
baseurl=http://mirrors.163.com/centos/5/centosplus/$basearch/
gpgcheck=1
enabled=0
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-5
#contrib - packages by Centos Users
[contrib]
name=CentOS-$releasever - Contrib - 163.com
mirrorlist=http://mirrorlist.centos.org/?release=5&arch=$basearch&repo=contrib baseurl=http://mirrors.163.com/centos/5/contrib/$basearch/
gpgcheck=1
enabled=0
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-5
11. 核心参考资料
[1] Hadoop-Eclipse
Hadoop伪分布模式环境搭建及Eclipse插件配置
[2] Hive
hive的安装及常用命令
[3] yum配置
在RedHat Server 5.4上安装YUM
[4] HBase配置
Ubuntu10.04LTS配置Hadoop1.0.1+HBase 0.92.0
12. 其他
解决sendmail启动慢问题:关闭sendmail服务
chkconfig --level 123456 sendmail off
百度搜索“爱华网”,专业资料,生活学习,尽在爱华网