最近在看一本书,发现当我们不实践直接看原理是枯燥无味的,而实践过后反过来看原理,会觉得很多道理,很多感悟。就拿我自己做反面教材,说我是搜索引擎优化工作者,我对搜索引擎的工作方式和基本的抓取原理,更新策略都不懂。那么你呢?下面就分享下我的读书笔记,仅当新人扫盲。
在介绍搜索引擎爬虫的之前,首先了解爬虫把网页的分类,四种:
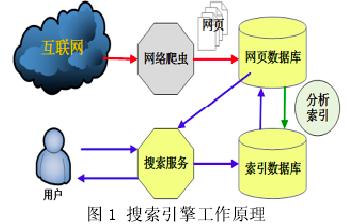
1,已过期的网页和已下载的网页
2,待下载的网页
3,可知网页
4,不可知网页
下面我会详细介绍搜索引擎是如何更新已下载网页,如何下载待下载网页,如何处理可知但未抓取的网页,如何抓取不可知网页。
一.处理待下载网页
抓取策略:在一堆可知的网页中,搜索引擎会抽出待抓取网页url,爬虫抓取网页url在其中顺序排列,形成一个队列,调度程序每次从队列头取出某个url,发送给网页下载器下载内容,每个新下载的页面包含的url会追加到带抓取队列中的末尾,形成循环,这是最基础的算法。但不是唯一的方法。
这样纯粹是按照顺序抓取,但是搜索引擎一般都选择重要的页面优先抓取。网页重要性,大部分是按照网页流行度抓取的,所为网页流行度,谷歌官方有句话是指曝光度,通俗意思就是反向链接。(所以才有那么多人做外链)
一般有四种方案选择重要页面:宽度优先遍历策略,非完全pagerank(非谷歌pr值)策略,ocip策略,大站优先策略
1、宽度优先遍历策略:将新下载的网页包含的链接直接追加到带抓取url队列末尾。看似很机械,其实包含了一些优先策略:如果入链比较多,就更加容易被宽度优先遍历策略抓取到,入链个数侧面表现了网页的重要性。(这就是为什么要做好站内链接)
2、非完全pagerank:前面的是以数量来定的,这个是加入了质量。
初始算法:将已下载的的网页加入待下载url队列中形成网页集合,在这个集合中计算pr,然后将带抓取的队列按照pr重新排列,就按照这个顺序抓取。
(每次新下载网页之后又要重新计算排序,显得效率太低了)
每当攒够k个网页之后在重新计算。但是问题是:新抽出来的网页没后计算pr没有pr值,他们的重要性可能比已经在队列中的要高怎么办?
解决办法:给每个新抽出来赋予一个临时pr,这个临时pr是根据入链传到的pr值汇总的值。这样在计算下,如果比队列中高就有限抓取他。这就是非完全pr
(pr高的会优先抓取,收录多排名靠前机会也大一些,所以会有那么多人提高spr)
3、ocip(online page importance computation)策略:在线页面重要性,改进的pr算法。
算法开始之前就每个页面都给一样的现金,,当这个页面被下载了以后,这个现金就平均分给他的导出页面,而自己的就清空。这些导出页面放在带抓取的队列中,按照现金多少来优先抓取。
和pr区别:pr上一个页面的不清空,每次都要迭代重新计算,而这个不用重新计算都清空了。而且pr存在无连接关系的跳转,而这个只要无连接就不传递现金。
4、大站优先:带抓取队列中哪个网站的多就优先抓取哪个。(所以网站页面要丰富,内容要丰富)
二、更新已下载网页
上面就是搜索引擎的抓取策略。抓取完了的页面就加入已下载的网页中,已下载的网页需要不断地更新,那么搜索引擎又是如何更新的呢?
一般的网页更新策略:历史参考策略,用户体验策略,聚类抽样策略
1、历史参考:过去频繁更新的,现在可能也频繁。利用模型预测未来更新时间。忽略导航栏和广告的频繁更新,所以导航的频繁更新没用,重在内容(现在知道为什么更新内容要持续,有规律了吧)
2、用户体验:即使网页已经过时了,需要更新了,但如果我更新了不影响用户体验搜索引擎就晚些更新。算法是:网页更新对搜索引擎搜索质量的影响(一般看排名),影响大就尽快更新。所以他们会保存多个历史网页,根据以前更新所带来的影响判断更新对搜索引擎质量的影响大小。
以上两种缺点:依赖历史,要保存很多历史数据,增加负担。如果没有历史记录就不准确了。
3、聚类抽样策略:把网页分类,根据同一类别网页更新频率更新所有这一类别的网页。抽取最具代表性的,看他的更新频率,以后同行业的都按照这个频率。
三、抓取不可知网页
不可知的网页就是暗网,搜索引擎很难用常规方法抓取到的数据。比如没有连接的网站,数据库。比如一个产品库存查询,可能要输入产品名称,地区,型号一系列文本才能查询库存数量。而搜索引擎是难以抓取的。这就有了查询组合和,isit算法。
先介绍下两个概念:
1、富含信息查询模版:就比如一个查询系统,我设定一个查询模版,每个文本框输入什么信号,地区,产品名称等,形成不同的查询组合。不同的组合之间差异很大,就是富含信息查询模版。
这个模板是怎么确定的呢?爬虫先从一维模版开始,比如先别的不是输入就输入地区,看是否是富含信息查询模版,是就扩展到二维模版,比如地区+型号。如此增加维度,直到没有新的模版。
2、词的组合:也许你纳闷了,爬虫怎么知道这个输入框要输入什么,是地区还是产品名称,还是时间?所以爬虫开始需要人工提示,人工提供一些初始查询种子表,爬虫更具这个表格查询下载页面,然后分析页面,自动挖掘新的关键词,形成新的查询列表,然后在查询,将结果提交给搜索引擎,直到没有新内容为止。
这样就完成了对暗网的抓取。
以上只是简单的介绍一下爬虫的抓取和更新框架,具体的算法可就复杂多了,有待我慢慢研究过后再分享。
最后感谢站长网的支持,本文由网站http://www.haoyunlaibj.com小编一个字一个字码出来的,转载请保留链接哦