Cortex-M3是一个32位的核,在传统的单片机领域中,有一些不同于通用32位CPU应用的要求。谭军举例说,在工控领域,用户要求具有更快的中断速度,Cortex-M3采用了Tail-Chaining中断技术,完全基于硬件进行中断处理,最多可减少12个时钟周期数,在实际应用中可减少70%中断。单片机的另外一个特点是调试工具非常便宜,不象ARM的仿真器动辄几千上万。针对这个特点,Cortex-M3采用了新型的单线调试(Single Wire)技术,专门拿出一个引脚来做调试,从而节约了大笔的调试工具费用。同时,Cortex-M3中还集成了大部分存储器控制器,这样工程师可以直接在MCU外连接Flash,降低了设计难度和应用障碍。
cortex_Cortex -概述
Cortex-M3是一个32位处理器内核。内部的数据路径是32位的,寄存器是32位的,存储器接口也是32位的。CM3采用了哈佛结构,拥有独立的指令总线和数据总线,可以让取指与数据访问并行不悖。这样一来数据访问不再占用指令总线,从而提升了性能。为实现这个特性,CM3内部含有好几条总线接口,每条都为自己的应用场合优化过,并且它们可以并行工作。但是另一方面,指令总线和数据总线共享同一个存储器空间(一个统一的存储器系统)。换句话说,不是因为有两条总线,可寻址空间就变成8GB了。
比较复杂的应用可能需要更多的存储系统功能,为此CM3提供一个可选的MPU,而且在需要的情况下也可以使用外部的cache。另外在CM3中,Both小端模式和大端模式都是支持的。
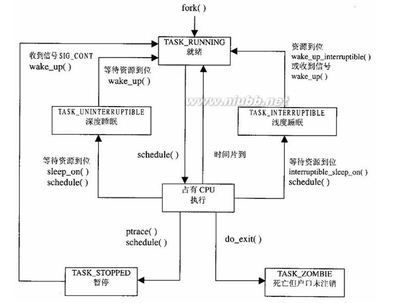
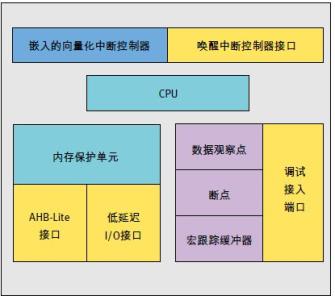
CM3内部还附赠了好多调试组件,用于在硬件水平上支持调试操作,如指令断点,数据观察点等。另外,为支持更高级的调试,还有其它可选组件,包括指令跟踪和多种类型的调试接口。
cortex_Cortex -内核架构
ARMCortex-M3采用哈佛结构,并选择了适合于微控制器应用的三级流水线,但增加了分支预测功能。
现代处理器大多采用指令预取和流水线技术,以提高处理器的指令执行速度。流水线处理器在正常执行指令时,如果碰到分支(跳转)指令,由于指令执行的顺序可能会发生变化,指令预取队列和流水线中的部分指令就可能作废,而需要从新的地址重新取指、执行,这样就会使流水线“断流”,处理器性能因此而受到影响。特别是现代C语言程序,经编译器优化生成的目标代码中,分支指令所占的比例可达10-20%,对流水线处理器的影响会的更大。为此,现代高性能流水线处理器中一般都加入了分支预测部件,就是在处理器从存储器预取指令时,当遇到分支(跳转)指令时,能自动预测跳转是否会发生,再从预测的方向进行取指,从而提供给流水线连续的指令流,流水线就可以不断地执行有效指令,保证了其性能的发挥。
ARMCortex-M3内核的预取部件具有分支预测功能,可以预取分支目标地址的指令,使分支延迟减少到一个时钟周期。
针对业界对ARM处理器中断响应的问题,Cortex-M3首次在内核上集成了嵌套向量中断控制器(NVIC)。Cortex-M3的中断延迟只有12个时钟周期(ARM7需要24-42个周期);Cortex-M3还使用尾链技术,使得背靠背(back-to-back)中断的响应只需要6个时钟周期(ARM7需要大于30个周期)。Cortex-M3采用了基于栈的异常模式,使得芯片初始化的封装更为简单。
Cortex-M3加入了类似于8位处理器的内核低功耗模式,支持3种功耗管理模式:通过一条指令立即睡眠;异常/中断退出时睡眠;深度睡眠。使整个芯片的功耗控制更为有效。
cortex_Cortex -特点
高性能
? 许多指令都是单周期的――包括乘法相关指令。并且从整体性能上,Cortex-M3比得过绝大多数其它的架构。
? 指令总线和数据总线被分开,取值和访内可以并行不悖
? Thumb-2的到来告别了状态切换的旧世代,再也不需要花时间来切换于32位ARM状态和16位Thumb状态之间了。这简化了软件开发和代码维护,使产品面市更快。
? Thumb-2指令集为编程带来了更多的灵活性。许多数据操作现在能用更短的代码搞定,这意味着Cortex-M3的代码密度更高,也就对存储器的需求更少。
? 取指都按32位处理。同一周期最多可以取出两条指令,留下了更多的带宽给数据传输。
? Cortex-M3的设计允许单片机高频运行(现代半导体制造技术能保证100MHz以上的速度)。即使在相同的速度下运行,CM3的每指令周期数(CPI)也更低,于是同样的MHz下可以做更多的工作;另一方面,也使同一个应用在CM3上需要更低的主频。
2.11.2 先进的中断处理功能
? 内建的嵌套向量中断控制器支持多达240条外部中断输入。向量化的中断功能剧烈地缩短了中断延迟,因为不再需要软件去判断中断源。中断的嵌套也是在硬件水平上实现的,不需要软件代码来实现。
? Cortex-M3在进入异常服务例程时,自动压栈了R0-R3, R12, LR, PSR和PC,并且在返回时自动弹出它们,这多清爽!既加速了中断的响应,也再不需要汇编语言代码了(第8章有详述)。
? NVIC支持对每一路中断设置不同的优先级,使得中断管理极富弹性。最粗线条的实现也至少要支持8级优先级,而且还能动态地被修改。
? 优化中断响应还有两招,它们分别是“咬尾中断机制”和“晚到中断机制”。
? 有些需要较多周期才能执行完的指令,是可以被中断-继续的――就好比它们是一串指令一样。这些指令包括加载多个寄存器(LDM),存储多个寄存器(STM),多个寄存器参与的PUSH,以及多个寄存器参与的POP。
? 除非系统被彻底地锁定,NMI(不可屏蔽中断)会在收到请求的第一时间予以响应。对于很多安全-关键(safety-critical)的应用,NMI都是必不不可少的(如化学反应即将失控时的紧急停机)。
低功耗
? Cortex-M3需要的逻辑门数少,所以先天就适合低功耗要求的应用(功率低于0.19mW/MHz)在内核水平上支持节能模式(SLEEPING和SLEEPDEEP位)。通过使用“等待中断指令(WFI)”和“等待事件指令(WFE)”,内核可以进入睡眠模式,并且以不同的方式唤醒。另外,模块的时钟是尽可能地分开供应的,所以在睡眠时可以把CM3的大多数“官能团”给停掉。
? CM3的设计是全静态的、同步的、可综合的。任何低功耗的或是标准的半导体工艺均可放心饮用。
系统特性
? 系统支持“位寻址带”操作(8051位寻址机制的“威力大幅加强版”),字节不变的大端模式,并且支持非对齐的数据访问。
? 拥有先进的fault处理机制,支持多种类型的异常和faults,使故障诊断更容易。
? 通过引入banked堆栈指针机制,把系统程序使用的堆栈和用户程序使用的堆栈划清界线。如果再配上可选的MPU,处理器就能彻底满足对软件健壮性和可靠性有严格要求的应用。
调试支持
? 在支持传统的JTAG基础上,还支持更新更好的串行线调试接口。
? 基于CoreSight调试解决方案,使得处理器哪怕是在运行时,也能访问处理器状态和存储器内容。
? 内建了对多达6个断点和4个数据观察点的支持。
? 可以选配一个ETM,用于指令跟踪。数据的跟踪可以使用DWT
? 在调试方面还加入了以下的新特性,包括fault状态寄存器,新的fault异常,以及闪存修补 (patch)操作,使得调试大幅简化。
? 可选ITM模块,测试代码可以通过它输出调试信息,而且“拎包即可入住”般地方便使用。
cortex_Cortex -产品概述
cortex-m3
单片机的另外一个特点是调试工具非常便宜,不象ARM的仿真器动辄几千上万。针对这个特点,Cortex-M3采用了新型的单线调试(Single Wire)技术,专门拿出一个引脚来做调试,从而节约了大笔的调试工具费用。同时,Cortex-M3中还集成了大部分存储器控制器,这样工程师可以直接在MCU外连接Flash,降低了设计难度和应用障碍。
ARM Cortex-M3处理器结合了多种突破性技术,令芯片供应商提供超低费用的芯片,仅33000门的内核性能可达1.2DMIPS/MHz。该处理器还集成了许多紧耦合系统外设,令系统能满足下一代产品的控制需求。ARM公司希望Cortex-M3核的推出,能帮助单片机厂商。
Cortex的优势应该在于低功耗、低成本、高性能3者(或2者)的结合。
Cortex如果能做到 合理的低功耗(肯定要比Arm7 & Arm9要低,但不大可能比430、PIC、AVR低) + 合理的高性能(10~50MIPS是比较可能出现的范围) + 适当的低成本(1~5$应该不会奇怪)。
简单的低成本不大可能比典型的8位MCU低。对于已经有8位MCU的厂商来说,比如Philips、Atmel、Freescale、Microchip还有ST和Silocon Lab,不大可能用Cortex来打自己的8位MCU。对于没有8位MCU的厂商来说,当然是另外一回事,但他们在国内进行推广的实力在短期内还不够。
对于已经有32位ARM的厂商来说,比如Philips、Atmel、ST,又不大可能用Cortex来打自己的Arm7/9,对他们来说,比较合理的定位把Cortex与Arm7/9错开,即
对于仍然在推广16位MCU的厂商来说,比如Freescal、Microchip,处境比较尴尬,因为Cortex基本上可以完全替代16位MCU。
所以,未来的1~2年,来自新厂商的Cortex比较值得期待-包括国内的供应商;对于已有32位ARM的厂商,情况比较有趣;对于16位MCU的厂商,反应比较有意思。
cortex_Cortex -编程模式
Cortex-M3处理器采用ARMv7-M架构,它包括所有的16位Thumb指令集和基本的32位Thumb-2指令集架构,Cortex-M3处理器不能执行ARM指令集。
Thumb-2在Thumb指令集架构(ISA)上进行了大量的改进,它与Thumb相比,具有更高的代码密度并提供16/32位指令的更高性能。
关于工作模式
Cortex-M3处理器支持2种工作模式:线程模式和处理模式。在复位时处理器进入“线程模式”,异常返回时也会进入该模式,特权和用户(非特权)模式代码能够在“线程模式”下运行。
出现异常模式时处理器进入“处理模式”,在处理模式下,所有代码都是特权访问的。
关于工作状态
Coretx-M3处理器有2种工作状态。
Thumb状态:这是16位和32位“半字对齐”的Thumb和Thumb-2指令的执行状态。
调试状态:处理器停止并进行调试,进入该状态。
cortex_Cortex -M3
Keil ULINK 仿真器
IAR JLink 仿真器
对客户来说用什么技术、芯片不是主要的。主要的是能否满足要求。高性价比、开发门槛底、易于使用才是硬道理。Cortex M3从理论上来说是高性价比。但目前已有的芯片的功能太少。Cortex M系列在处理能力基本与ARM7同,主要是成本低,功耗小。如果周立功自己来做加上丰富的外设,如UART/USB/MAC以及无线通讯等功能,加上FLASH、RAM这样的SOC可以替换现在的许多应用,但这样的话不知道什么时候可以看到成品。内核是好,外设也是很重要的。
cortex_Cortex -产品构造
synchronous serial 总线
完全可编程的16C550-型 UART
两个独立的模拟比较器
可配置为输出来驱动一个输出引脚,或产生一个中断
可在外部输入引脚或外部输入引脚和内部参考电压之间比较
2到18个GPIO 这取决于用户的配置
在所有的引脚上具有可编程的GPIO中断,可以边沿触发或电平触发
可编程的GPIO 衬垫配置:
弱上拉或下拉电阻
2 mA, 4 mA, and 8 mA 衬垫驱动
8 mA驱动斜率控制
开漏使能
数字输入使能
片内LDO电压调整器
处理器低功率选项:睡眠模式和深度睡眠模式
外设低功率选项:软件控制关闭个别外设
用户使能的LDO 未调整电压检测和自动复位
通过中断或复位方式检测并报告3.3 V 电源电压下降
IEEE 1149.1-1990 兼容的TAP控制器
经过 JTAG 或串行线调试
28脚SOIC
商业或工业级工作温度
LM3S316 比 LM3S101 的增强如下:
25 MHz下工作
8级优先级的24个中断通道
16 kB 的单周期flash存储器,在2 kB块的基础上提供2种形式的flash保护。
4 kB 的单周期SRAM存储器
4 通道 10-bit ADC 250K采样/秒
片内温度传感器
4个专用的电机控制PWM 输出
I2C 主从收发 传输速度100 kbps标准模式 400 kbps高速模式
3到32个GPIO 这取决于用户的配置
48脚SOIC
cortex_Cortex -主要控制
LM3S101 是一个高性能的ARM® Cortex?-M3 v7M架构的微控制器,适用于成本敏感的应用。它支持完全兼容Thumb的Thumb-2-only指令集,具有硬件除法和单周期的乘法器。集成的嵌套式的中断控制器(NVIC)提供确定性的中断处理。目标应包括:工厂自动化及控制,工业控制动力设备,以及楼宇家庭自动化。
cortex_Cortex -产品特性
32位ARM?Cortex?-M3v7M架构
Thumb兼容的Thumb-2-only指令集
20MHz下工作
硬件除法和单周期的乘法器
集成的嵌套式的中断控制器(NVIC)提供确定性的中断处理
8级优先级的14个中断通道
8kB的单周期flash存储器,在2kB块的基础上提供2种形式的flash保护。
2kB的单周期SRAM存储器
2个定时器
每个可被配置为一个32位的定时器或两个16位的定时器
一个支持捕捉和简单的PWM模式
实时时钟(RTC)
独立的看门狗定时器
可编程的接口支持:FreescaleSPI总线,NationalSemiconductorMICROWIRE总线,Texas
cortex_Cortex -M3
型号LM3S101LM3S102LM3S301M3S310LM3S315LM3S316
封装28-pinSOIC 28-pinSOIC 48-pinLQFP 48-pinLQFP 48-pinLQFP 48-pinLQFP
工作温度C,IC,IC,IC,IC,IC,I
(商业级C 0 to 70°C;
工业级I