语音识别技术,也被称为自动语音识别Automatic Speech Recognition,(ASR),其目标是将人类的语音中的词汇内容转换为计算机可读的输入。
语音识别技术语音识别技术
语音识别技术就是让机器通过识别和理解过程把语音信号转变为相应的文本或命令的高技术,也就是让机器听懂人类的语音。也就是说,如果电脑配置有“语音辨识”的程序组,那么当你的声音通过一个转换装置输入电脑内部、并以数位方式储存后,语音辨识程序便开始以你输入的声音样本与事先储存好的声音样本进行对比工作。声音对比工作完成之后,电脑就会输入一个它认为最“象”的声音样本序号,就可以知道你刚才念的声音是什么意义,进而执行此命令。说起来简单,但要真正建立辨识率高的语音辨识程序组,却是非常困难而专业的,世界各地的学者们也还在努力研究最好的方式。专家学者们研究出许多破解这个问题的方法,如傅立叶转换、倒频谱参数等,使目前的语音辨识系统已达到一个可接受的程度,并且辨识度愈来愈高。
语音识别技术_语音识别技术 -语音识别系统分为
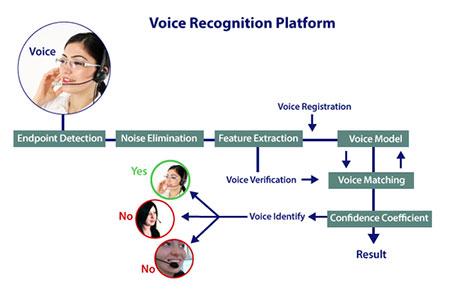
计算机语音识别过程与人对语音识别处理过程基本上是一致的。目前主流的语音识别技术是基于统计模式识别的基本理论。一个完整的语音识别系统可大致分为三部分:
(1)语音特征提取:目的是从语音波形中提取随时间变化的语音特征序列。
(2)声学模型与模式匹配(识别算法):声学模型是识别系统的底层模型,并且是语音识别系统中最关键的一部分。声学模型通常由获取的语音特征通过训练产生,目的是为每个发音建立发音模板。在识别时将未知的语音特征同声学模型(模式)进行匹配与比较,计算未知语音的特征矢量序列和每个发音模板之间的距离。声学模型的设计和语言发音特点密切相关。声学模型单元大小(字发音模型、半音节模型或音素模型)对语音训练数据量大小、系统识别率,以及灵活性有较大影响。
(3)语义理解:计算机对识别结果进行语法、语义分析。明白语言的意义以便做出相应的反应。通常是通过语言模型来实现。
语音识别技术_语音识别技术 -语音识别技术的应用
语音识别技术所谓“语音识别”,就是利用电子计算机等机械装置来识别人讲话的意义和内容。20世纪50代,就有人提出“口授打印机”的设恕。可以说,这是有关语音识别技术最早构想。
语音识别技术经历了语音识别、语音合成以及自然语音合成3个阶段。从原理上讲,似乎让计算机识别人的语言并不难,其实困难还是不少的。例如,不同的人读同一个词所发出的音在声学特征上却不完全相同;即便是同一个人,右不同情况下对同一个字的发音也不相同。加上人们讲话时常有不合语法规律的情况,有时还夹杂些俗语,或省略一些词语,而且语速变化不定。所有这些,在我们听别人讲话时似乎都不成为问题,但让机器理解则很是困难。近年来,由于计算机功能的日益强大,存储技术、语音算法技术和信号处理技术的长足进步,以及软件编程水平的提高,语音识别技术已经取得突破性的进展,使它的广泛应用成为可能。
语音识别技术的应用主要有以下两个方面。一是用于人机交流。目前这方面应用的呼声很高,因为使用键盘、鼠标与电子计算机进行交流的这种方式,使许多非专业人员,特别是不懂英语或不熟悉汉语拼音的人被拒之于门外,影响到电子计算机的进一步普及。语音识别技术的采用,改变了人与计算机的互动模式,人们只需动动口,就能打开或关闭程序,改变工作界面。这种使电脑人性化的结果是使人的双手得到解放,使每个人都能操作和应用计算机。电话仍是目前使用最为普遍的通信工具,通过电话与语音识别系统的协同工作,可以实现语音拨号、电话购物以及通过电话办理银行业务、炒股、上网检索信息或处理电子件等。不久,能按主人口令接通电话、打开收音机,以及通过声纹识别来者身份的安全系统也将获得应用。
语音识别技术的另一方面应用便是语音输入和合成语音输出。现在,已经出现能将口述的文稿输入计算机并按指定格式编排的语音软件,它比通过键盘输入在速度上要提高2~4倍。装有语音软件的电脑还能通过语音合成把计算机里的文件用各种语言“读”出来,这将大大推进远程通信和网络电话的发展。
在现阶段,语音技术主要用于电子商务、客户服务和教育培训等领域,它对于节省人力、时间,提高工作效率将起到明显的作用。能实现自动翻译的语音识别系统目前也正在研究、完善之中。
语音识别是一门交叉学科。近二十年来,语音识别技术取得显著进步,开始从实验室走向市场。人们预计,未来 10 年内,语音识别技术将进入工业、家电、通信、汽车电子、医疗、家庭服务、消费电子产品等各个领域。
语音识别技术_语音识别技术 -大致分为三部分
计算机语音识别过程与人对语音识别处理过程基本上是一致的。目前主流的语音识别技术是基于统计模式识别的基本理论。一个完整的语音识别系统可大致分为三部分:
1、 语音特征提取:其目的是从语音波形中提取出随时间变化的语音特征序列。
2、 声学模型与模式匹配(识别算法):声学模型通常将获取的语音特征通过学习算法产生。在识别时将输入的语音特征同声学模型(模式)进行匹配与比较,得到最佳的识别结果。
3、语言模型与语言处理:语言模型包括由识别语音命令构成的语法网络或由统计方法构成的语言模型,语言处理可以进行语法、语义分析。对小词表语音识别系统,往往不需要语言处理部分.
语音识别技术_语音识别技术 -来自
"http://baike.eccn.com/eewiki/index.php/%E8%AF%AD%E9%9F%B3%E8%AF%86%E5%88%AB%E6%8A%80%E6%9C%AF"