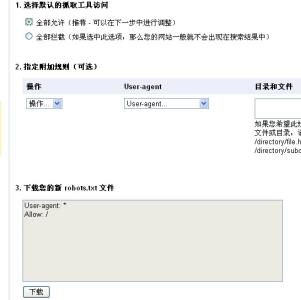
robots.txt文件是搜索引擎的口令牌,因此设计要相当谨慎,有很多细节我们需要注意的,如果我们没有注意这些细节,后果无法估计。robots.txt文件是搜索引擎进入我们的站点后首先访问的文件,现在我们就来看看设置robots文件该注意哪些。 错误一:Allow与disallow顺序颠倒 首先我们来看一段robots.txt语句: User-agent: * Allow: / Disallow: /abcd/ 这段语句初看我们可以得到目的是告诉搜索引擎在abcd目录下面的页面不能抓取,但是其他所有的页面可以。但是这段语句的实际效果如何呢?效果是背道而驰的,为什么呢?我们知道搜索引擎蜘蛛对于robots文件中的规则的执行是从上到下的。这将会造成Disallow语句失效,正确的做法,是要把Disallow: /abcd/置于Allow: /前才能发挥我们想要的效果。 错误二:屏蔽某一个页面时,页面名前没有带上斜杠“/” 我想这一点很多站长也很容易忽视掉,打个比方,我们想要对搜索引擎屏蔽在根目录下的abcd.html这一页面,有的人在robots上可能会这么写:Disallow: abcd.html,表面上看可能没什么问题,但是笔者想要问一下你先告知搜搜引擎屏蔽的这一页面在什么目录下面?如果我们不带上的话,搜索引擎蜘蛛无法识别是在哪一个页面。正确的写法是:Disallow: /abcd.html,这样才能真正的屏蔽位于根目录下面的abcd.html这一页面。 错误三:屏蔽的后面没有跟上斜杠“/” 同样举个例子,比如我们想屏蔽/abcd/这一目录下面的页面,有的人可能会这样写Disallow: /abcd。这样写是否有问题呢?这样写依然有问题,而且问题很大条。这样虽然可以屏蔽掉/abcd/这一目录下面的所有页面。但是这也会传递给搜索引擎这样的信息,那就是屏蔽开头为/abcd的所有页面。效果等同于是Disallow: /abcd’*。这个错误将会给站点照成很大的影响。正确的做法是,在想要屏蔽的目录后面切记需要加上斜杠“/”。