经太过析站点日记Log文件我们可以看到用户和搜索引擎蜘蛛拜访网站的举止数据,这些数据能让我们阐发出用户与蜘蛛对站点的喜好以及站点的健康环境。在站点日记阐发中,咱们首要需要赏析的是蜘蛛举止。
在蜘蛛爬取及收录过程中,搜寻引擎会给特定权重站点分拨响应的资源量。一个搜寻引擎朋友型的站点理应虚浮操作这些资源,让蜘蛛可以急迅、精确、周全的爬取有价格、用户爱情的形式,而不撙节资源在无用的、走访异常的内容上。
但由于web日志中数据量过大,所以咱们一般需要凭借web日记赏析工具来检查。经常使用的日记阐发工具有:光年日记解析工具、web log exploer。
在 赏析日记时,对于单日日志文件咱们需要解析的形式有:接见次数、搁浅岁月、抓取量、目次抓取统计、页面抓取统计、蜘蛛接见IP、HTTP状态码、 蜘蛛纳闷时段、蜘蛛爬取路子等;对于多日日记文件咱们需要剖析的内容有:蜘蛛会晤次数趋向、搁浅时日趋向、个人抓取趋势、各目次抓取趋向、抓取年华段、蜘 蛛烦懑周期等。
下面小脑袋直通车竞价软件小编来看看网站日记若何解析?
网站日记数据剖析解读:
1、接见次数、进展岁月、抓取量
从这三项数据中咱们可以获悉:均匀每次抓取页面数、单页抓取停留岁月和平均每次搁浅岁月。
匀称每次抓取页面数=总抓取量/走访次数
单页抓取停顿=每次停顿/每次抓取
平均每次停留年华=总搁浅时间/会晤次数
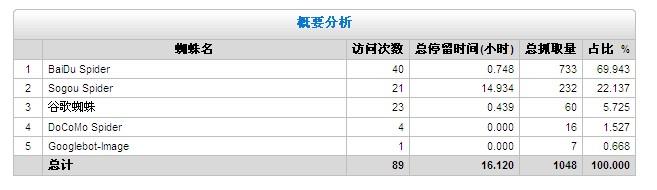
从 这些数据我们可以看出蜘蛛的生动程度、亲和程度、抓取深度等,总会见次数、进展光阴、抓取量越高、平均抓取页面、平均搁浅时间,剖明站点越受搜寻 引擎喜欢。而单页抓取停顿时间诠释站点页面拜访速率,时间越长,抒发网站接见速度越慢,对搜索引擎抓取收录较有利,咱们应只管即便行进网页加载速度,削减 单而立进展时间,让爬虫本钱更多的去抓取收录。
其他,依据这些数据咱们还可以统计出一段光阴内,站点的总体趋向透露表现,如:蜘蛛会面次数趋向、停顿工夫趋向、抓取趋向。
2、抓取统计
经 由日志解析我们可以看到站点哪些目次受蜘蛛LOVE、抓取目次深度、紧要页风貌录抓取状况、有用页风仪录抓取状况等。通过相比目录下页面抓取及收 录环境,咱们可以缔造更多问题。对于需要目次,我们需要经过表里调停增长权重及爬取;对付有用页面,在robots.txt中发展屏蔽。
另外,通适量日日记统计,我们可以看到站表里举止给目录带来的成效,优化是否合理,能否达到了预期功效。对于抗衡目录,以持久时日段来看,我们可以看到该目次下页面显露,按照举动揣度闪现的缘由等。
3、页面抓取
在站点日志阐发中,咱们可以看到详细被蜘蛛爬取的页面。在这些页面中,我们可以阐发出蜘蛛爬取了哪些需要被阻止爬取的页面、爬取了哪些无收录价格页面、爬取了哪些频频页面url等,为充足哄骗蜘蛛利润我们需要将这些地点在robots.txt中制止爬取。
其 余,我们还可以剖析未收录页面启事,对付新文章,是因为没有被爬取到而未收录抑或爬取了但未放出。关于某些阅读意思不大的页面,笼统咱们需要它作 为爬取通道,对付这些页面,咱们可否应当做Noindex标签等。但从另一方面讲,蜘蛛会弱智到靠这些无含义的通道页爬取页面吗,蜘蛛不懂 sitemap?【对此,笔者有不解,求分享教导】
4、蜘蛛拜访IP
曾经有人提出过经由蜘蛛的ip段来武断站点的降权环境,笨鸟感触这个含意不大,因为这个后知性太强了。何况降权更多理应从前三项数据来判断,用单单一个ip段来果决含义不大。IP剖析的更多用场理应是果决能否具备囊括蜘蛛、假蜘蛛、恶意点击蜘蛛等。
5、访问外形码
蜘蛛时时涌现的形状码如301、404等,呈现这些形状码要及时处置惩罚,以防止对web造成欠安的影响。
6、抓取时间段
通适度析比拟多个单日蜘蛛小时爬取量,我们可以认识到特定蜘蛛对于本web在特守光阴的沉闷时段。经由过程比拟周数据,咱们可以看到特定蜘蛛在一周中的生动周期。明确这个,对付站点形式更新工夫有定然率领含义,而之前所谓小三大四等均为不科学说法。
7、蜘蛛爬取途径
在 站点日志中我们可以跟踪到特定IP的接见阶梯,假定咱们跟踪特定蜘蛛的会见蹊径则能发现关于本web构造下蜘蛛的爬取阶梯喜好。由此,我们可以恰 当的引导蜘蛛的爬取阶梯,让蜘蛛更多的爬取需要、有价钱、新更新页面。此中爬取蹊径中咱们双可以综合页面物理构造途径喜好以及url逻辑组织爬取爱好。通 过这些,可以让我们从搜寻引擎的视角去扫视本身的站点。
(本文由小脑袋百度360直通车竞价软件试用站提供 转载请保留)